
写在前面
其实之前就发现搞CS的很喜欢在自己个人站里保存学习笔记。我依稀记得在我上中小学的时候还是非常喜欢记笔记的,大一的时候上数学课的时候也是。但是接触计算机课程多了以后,觉得自己写总是太浪费时间,就总是完全不记笔记或者找资料东拼西凑再总结了。
但是论文这些东西就没法参照什么资料了,要有自己的理解、按自己的习惯消化才好。又要利于以后复习,所以我打算把看论文时记下的笔记保存在这里。
另外引一个我觉得不错的笔记:人工智能基础
很好的CV概括:计算机视觉四大基本任务(分类、定位、检测、分割)
嗯,感觉还是要回复一些总结整理的习惯。
从下面开始就是CV论文阅读笔记了。本文为第一篇。
MASK R-CNN
arXiv:1703.06870v3 [cs.CV] 24 Jan 2018
Kaiming He, Georgia Gkioxari, Piotr Doll ́ar, Ross Girshick, Facebook AI Research (FAIR)
R-CNN已经是成熟的技术了,这方面还是有比较好的笔记,我暂不动笔
为了防止这篇文章寄了,摘录如下:
基础知识介绍
普通的深度学习监督算法主要是用来做分类,在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)竞赛以及实际的应用中,还包括目标定位和目标检测等任务。其中目标定位是不仅仅要识别出来是什么物体(即分类),而且还要预测物体的位置,位置一般用边框(bounding box)标记,如图1(2)所示。而目标检测实质是多目标的定位,即要在图片中定位多个目标物体,包括分类和定位。
目标检测对于人类来说并不困难,通过对图片中不同颜色模块的感知很容易定位并分类出其中目标物体,但对于计算机来说,面对的是RGB像素矩阵,很难从图像中直接得到狗和猫这样的抽象概念并定位其位置,再加上有时候多个物体和杂乱的背景混杂在一起,目标检测更加困难。
传统的目标检测算法
这难不倒科学家们,在传统视觉领域,目标检测就是一个非常热门的研究方向,一些特定目标的检测,比如人脸检测和行人检测已经有非常成熟的技术了。普通的目标检测也有过很多的尝试,但是效果总是差强人意。
传统的目标检测一般使用滑动窗口的框架,主要包括三个步骤:
- 利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;
- 提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征;行人检测和普通目标检测常用的HOG特征等;
- 利用分类器进行识别,比如常用的SVM模型。
R-CNN
R-CNN是Region-based Convolutional Neural Networks的缩写,中文翻译是基于区域的卷积神经网络,是一种结合区域提名(Region Proposal)和卷积神经网络(CNN)的目标检测方法。Ross Girshick在2013年的开山之作《Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation》奠定了这个子领域的基础,这篇论文后续版本发表在CVPR 2014,期刊版本发表在PAMI 2015。
其实在R-CNN之前已经有很多研究者尝试用Deep Learning的方法来做目标检测了,包括OverFeat,但R-CNN是第一个真正可以工业级应用的解决方案,这也和深度学习本身的发展类似,神经网络、卷积网络都不是什么新概念,但在本世纪突然真正变得可行,而一旦可行之后再迅猛发展也不足为奇了。
R-CNN这个领域目前研究非常活跃,先后出现了R-CNN、SPP-net、Fast R-CNN 、Faster R-CNN、R-FCN、YOLO、SSD等研究。Ross Girshick作为这个领域的开山鼻祖总是神一样的存在,R-CNN、Fast R-CNN、Faster R-CNN、YOLO都和他有关。这些创新的工作其实很多时候是把一些传统视觉领域的方法和深度学习结合起来了,比如选择性搜索(Selective Search)和图像金字塔(Pyramid)等。
R-CNN:针对区域提取做CNN的object detction。
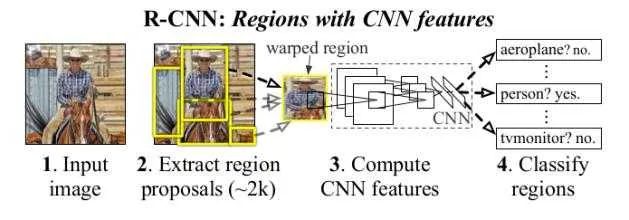
R-CNN基本步骤:
- 输入测试图像;
- 利用selective search(SS)算法在图像中从上到下提取2000个左右的Region Proposal;
- 将每个Region Proposal缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征;
- 将每个Region Proposal提取的CNN特征输入到SVM进行分类;
- 对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标。
缺陷:
- 训练分为多个阶段,步骤繁琐:微调网络+训练SVM+训练边框回归器;
- 训练耗时,占用磁盘空间大;5000张图像产生几百G的特征文件;
- 速度慢:使用GPU,VGG16模型处理一张图像需要47s;
- 测试速度慢:每个候选区域需要运行整个前向CNN计算;
- SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新。
FAST R-CNN
Fast R-CNN:区域提取转移到Feature Map之后做,这样不用对所有的区域进行单独的CNN Forward步骤。同时最终一起回归bounding box和类别。
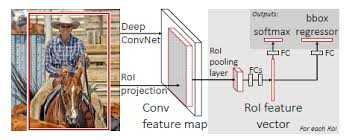
Fast R-CNN基本步骤:
- 输入测试图像;
- 利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
- 将整张图片输入CNN,进行特征提取;
- 把建议窗口映射到CNN的最后一层卷积feature map上;
- 通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
- 利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练。
与R-CNN对比的不同:
- 最后一层卷积层后加了一个ROI pooling layer;
- 损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。
改进:
- 测试时速度慢:R-CNN把一张图像分解成大量的建议框,每个建议框拉伸形成的图像都会单独通过CNN提取特征.实际上这些建议框之间大量重叠,特征值之间完全可以共享,造成了运算能力的浪费。FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享。
- 训练时速度慢:R-CNN在训练时,是在采用SVM分类之前,把通过CNN提取的特征存储在硬盘上.这种方法造成了训练性能低下,因为在硬盘上大量的读写数据会造成训练速度缓慢。FAST-RCNN在训练时,只需要将一张图像送入网络,每张图像一次性地提取CNN特征和建议区域,训练数据在GPU内存里直接进Loss层,这样候选区域的前几层特征不需要再重复计算且不再需要把大量数据存储在硬盘上。
- 训练所需空间大:R-CNN中独立的SVM分类器和回归器需要大量特征作为训练样本,需要大量的硬盘空间.FAST-RCNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储。
FASTER R-CNN
Faster R-CNN基本步骤:
- 输入测试图像;
- 将整张图片输入CNN,进行特征提取;
- 用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
- 把建议窗口映射到CNN的最后一层卷积feature map上;
- 通过RoI pooling层使每个RoI生成固定尺寸的feature map;
- 利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
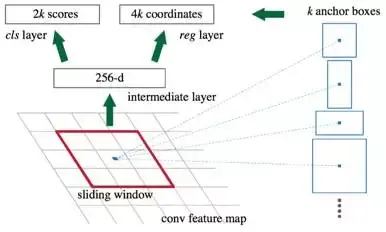
相比Faster-RCNN,主要两处不同:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享
改进:
Faster-RCNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高。
三种目标检测神经网络对比说明
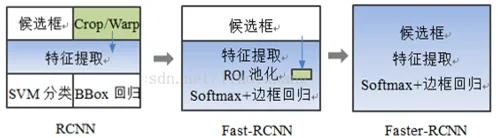
RCNN :
- 在图像中确定约1000-2000个候选框 (使用选择性搜索);
- 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取 ;
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ;
- 对于属于某一特征的候选框,用回归器进一步调整其位置。
Fast RCNN :
- 在图像中确定约1000-2000个候选框 (使用选择性搜索);
- 对整张图片输进CNN,得到feature map;
- 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框 的卷积特征输入到SPP layer和之后的层;
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ;
- 对于属于某一特征的候选框,用回归器进一步调整其位置。
Faster RCNN :
- 对整张图片输进CNN,得到feature map;
- 卷积特征输入到RPN,得到候选框的特征信息;
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ;
- 对于属于某一特征的候选框,用回归器进一步调整其位置。
之前在知乎上看到一位大佬对这个的总结,我觉得很有趣,在放在里面,大家看看有没有对这些算法的理解更清晰了些。
RCNN:用SS去选框,CNN提特征,SVM分类。BB盒回归。
Fast:RCNN上面的stage互不相关,就统一起来(实际上只统一了后面三个步骤),最大的改进在”在训练过程中,SGD的mini-batch选取是有“层次的”,同一张图片上的ROI在BP的时候会使用相同的原始图像。举个例子,当N=2,R=128的时候,相当于只BP了2张图像(但实际上是128个ROI)。
Faster:SS太慢,丫的,也用CNN给你整进去,这样就更快了。
以上就是现在三种目标检测领域三种算法的对比和说明,而在2017年2月何凯明等人又提出来了Mask R-CNN,是目前最好的目标检测算法,再一次基于Faster R-CNN进行改进,大大减少了计算时间,所以下面我会着重介绍一下Mask R-CNN。
Mask R-CNN
Mask R-CNN 进行实例分割,就是要在每一个像素上都表示出来目标所属的具体类别。 完成类别检测,图像分割和特征点定位。
解决的问题:在时间上对Faster R-CNN进行了优化,并且提高准确度,最关键的是在像素级别进行特征点定位达到了将各个对象的边缘确定的效果。

Mask RCNN分成三个部分,第一个是主干网络用来进行特征提取,第二个是头结构用来做边界框识别(分类和回归),第三个就是mask预测用来对每一个ROI进行区分。主干网络使用的是50层的深度残差网络ResNet50和Feature Pyramid Network(FPN) 。Mask-RCNN 大体框架还是Faster-RCNN的框架,可以说在基础特征网络之后又加入了全连接的分割子网,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN是Faster R-CNN 上的扩展——在其已有的用于边界框识别分支上添加了一个并行的用于预测目标掩码的分支。Mask R-CNN的训练很简单,只是在R-CNN的基础增加了少量的计算量,大约为5fps
其中黑色部分为原来的 Faster-RCNN,红色部分为在 Faster网络上的修改:
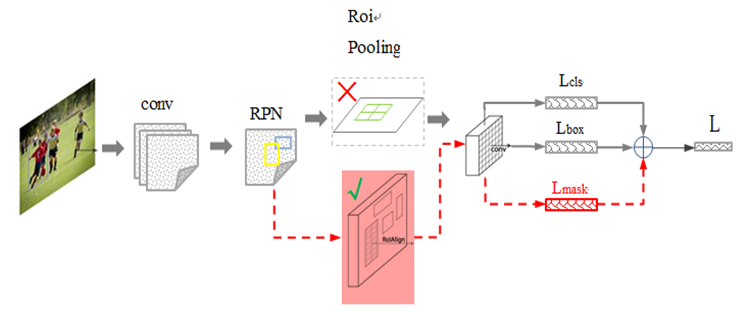
- 将Roi Pooling 层替换成了 Roi Align;
- 添加并列的 FCN层(mask 层);
先来概述一下Mask-RCNN 的几个特点(来自于 Paper 的 Abstract):
1)在边框识别的基础上添加分支网络,用于语义Mask 识别;
2)训练简单,相对于Faster 仅增加一个小的 Overhead,可以跑到 5FPS;
3)可以方便的扩展到其他任务,比如人的姿态估计等;
4)不借助Trick,在每个任务上,效果优于目前所有的 single-model entries,包括 COCO 2016 的Winners。
算法细节:
-
LOSS function
多任务损失函数对于每一个ROI,$L=L_{cls}+L_{box}+L_{mask}$.网络使用的损失函数为分类误差+检测误差+分割误差。分类误差和bounding box回归误差是faster R-CNN中的。分割误差为mask rcnn中新加的,对于每一个m*m大小的ROI区域,mask分支有一个K*m^2维的输出,K是指所有的类别,例如PASCAL VOC一共20个类别,加上背景,一共21个类别,K=21 。对于每一个像素,都是用sigmod函数求二值交叉熵(即对每个像素都进行逻辑回归),得到平均的二值交叉熵误差Lmask。对于每一个ROI,如果检测得到ROI属于哪一个分类,就只使用哪一个分支的交叉熵误差作为误差值进行计算。也就是一个ROI区域中K*m^2的输出,真正有用的只是某个类别的m^2的输出。(举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask。)这样的定义使得我们的网络不需要去区分每一个像素属于哪一类,只需要去区别在这个类当中的不同分别小类。
-
Mask Representation Mask
覆盖输入目标的空间位置,所以不能像类标和bbox一样通过全连接层坍塌到很短的向量。提取空间结构很自然的想到利用卷积的pixel to pixel 对应的特性。
具体的对每一个ROI预测一个mm大小的mask用FCN。这能保证mask 分支的每一层都明确的保持mm目标的空间布局,不会坍塌成缺少空间维度的向量。与前人工作使用全连接层预测mask相比,本文的FCN需要更少的参数,得到更好的效果。pixel to pixel 的任务需要ROI特征与原始输入图像有很好对齐来保持每个像素的空间对应。这就是提出RoIAlign层的动机。
-
RoIAlign
ROIpool是对ROI提取小的特征映射标准的操作符。量化导致了ROI和特征层的不对齐。这对分类任务没什么影响,但是对pixel to pixel的任务就有很大的负面影响。
为了解决这个问题,本文提出了RoIAlign层,移除ROIPool粗糙的量化,正确的对齐特征和输入。提出的改变非常简单:避免任何ROI边界或者bins的量化,即用x/16代替[x/16]。用双向性插值法输入特征在每个ROIbin的四个采样点的精确值。
-
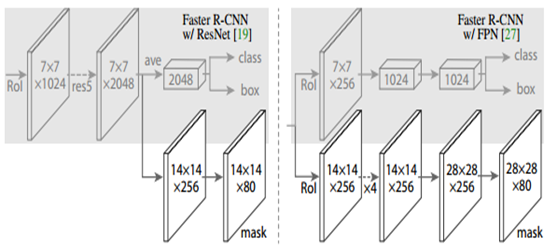
Network Architecture
将整个网络分成两部分,1)卷积主干结构用来提取整幅图像的特征。2)网络头用来对ROI进行bbox识别和mask预测。
分别考察50层和101层Resnet和ResNeXt网络作为卷积主干结构。还探索另一种有效的主干结构,叫作FPN。
结论
Mask R-CNN是一个小巧、灵活的通用对象实例分割框架(object instance segmentation)。它不仅可对图像中的目标进行检测,还可以对每一个目标给出一个高质量的分割结果。它在Faster R-CNN基础之上进行扩展,并行地在bounding box recognition分支上添加一个用于预测目标掩模(object mask)的新分支。该网络还很容易扩展到其他任务中,比如估计人的姿势,也就是关键点识别(person keypoint detection)。该框架COCO的一些列挑战任务重都取得了最好的结果,包括实例分割(instance segmentation)、候选框目标检测(bounding-box object detection)和人关键点检测(person keypoint detection)。