
写在前面
注意力机制在NLP领域和CV领域都有重要的应用,所以专门整理一下这边的知识点。
Paper: Attention is all You Need
另外,也需要贴一下transformet在cv这边重要应用论文:
DETR: End-to-End Object Detection with Transformers
基本结构
![]()
Word Embedding
we use learned embeddings to convert the input tokens and output tokens to vectors of dimension $d_{model}$.
在cv的目标识别中往往使用one-hot来标注不同类别的目标。但是one-hot会造成极大的空间浪费——要知道在NLP中,词汇量是非常大的。
因此,我们需要另一种词的表示方法,能够体现词与词之间的关系,使得意思相近的词有相近的表示结果,这种方法即 Word Embedding——核心是设计一个可学习的权重矩阵 $\mathbf{W}$,将词向量与这个矩阵进行点乘,即得到新的表示结果。
Position Encoding
接下来要加入位置信息。有公式(PE即Position Encoding):
\(PE_{(pos, 2i)} = \sin(pos/10000^{2i/d_{model}})\) \(PE_{(pos, 2i+1)} = \cos(pos/10000^{2i/d_{model}})\)
将单词的词 Embedding 和位置 Encoding 相加,就可以得到单词的表示向量 $X$,$X$ 就是 Transformer 的输入。
Self-Attention
这一部分是 Transformer 比较核心的内容。十分推荐李宏毅老师的讲解:Youtube
经过上一个步骤,我们获得了矩阵 $X$。其中,$X$的每一个行向量都表示一个单词进行 embed 之后的结果。
input X
embedded word 1
embedded word 2
embedded word 3
对于每一个单词,都生成一个 $q$(query) 向量、$k$(key) 向量和一个 $v$(value) 向量。$q$向量组成的矩阵$Q$和$k$向量组成的矩阵$K$进行运算,代表每个word对每个word的key进行query。这一步运算的公式是:
\[\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)\]由于矩阵乘法的特性,每个$q$都能和每个$k$进行运算,因此最后的计算结果带有全局的信息,也就是获取了全部的上下文。这一点是十分重要的。
关于这个神秘的$\sqrt{d_k}$,作者是这样说的:
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.
也就是说防止 $Q$ 和 $K$ 的点积值过大,softmax之后梯度太小。只是一个约定而已。
然后再与 $v$ 组成的 $V$ 矩阵做运算,获得最终的算式:
\[\mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]那么$Q$、$K$、$V$怎么获得呢?嗯那自然是学习出来的了。我们学习出三个线性变换矩阵 $W_Q$,$W_K$,$W_V$,然后用输入 $X$ 和它相乘:
\[X \times W_Q = Q\] \[X \times W_K = K\] \[X \times W_V = V\]由此计算得到 $Q$,$K$,$V$ 再做上面的计算就可以了。j记这一步的结果为 $Z$,这个计算过程的操作就是 Scaled Dot-Product Attention。
Multi-Head Attention
接下来就把多个 Self-Attention 拼接成一个 Multi-Head Attention。其实简单,直接把它们 concat 到一起再进行线性变换就可以了。下图展示了一种 $h = 8$ (8个Self-Attention)的情况。
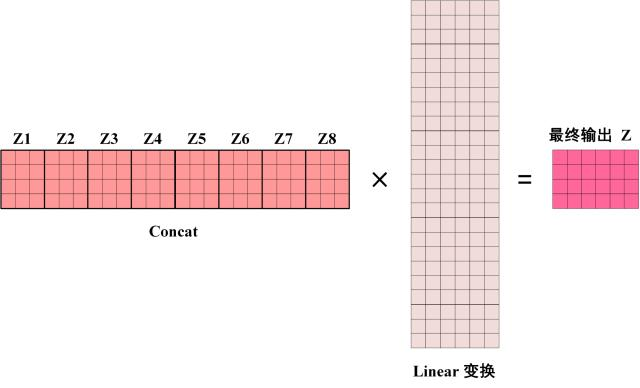
注意,Multi-Head Attention 的输出矩阵 $Z$ 和输入矩阵 $X$ 的维度是一样的。
Add & Norm
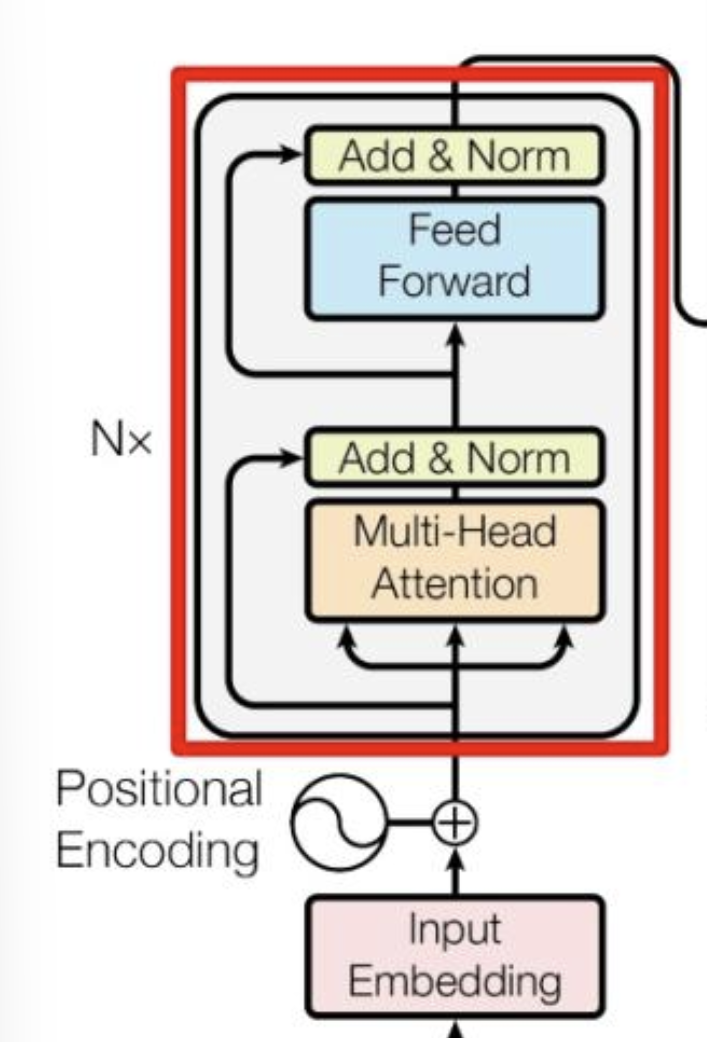
接下来是这一部分。
Add & Norm 层的公式是这样的:
\[\mathrm{LayerNorm}(X + \mathrm{MultiHeadAttention(X)})\] \[\mathrm{LayerNorm}(X + \mathrm{FeedForward(X)})\]这一段是受到了残差神经网络的影响。
Feed Forward
这一模块是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。
\[\max(0, XW_1 + b_1)W_2 + b_2\]Encoder
综上所述,一个 Encoder Block 中的所有组件都被介绍完毕了。
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 $X_{(n \times d)}$,并输出一个矩阵$O_{(n \times d)}$。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
Decoder
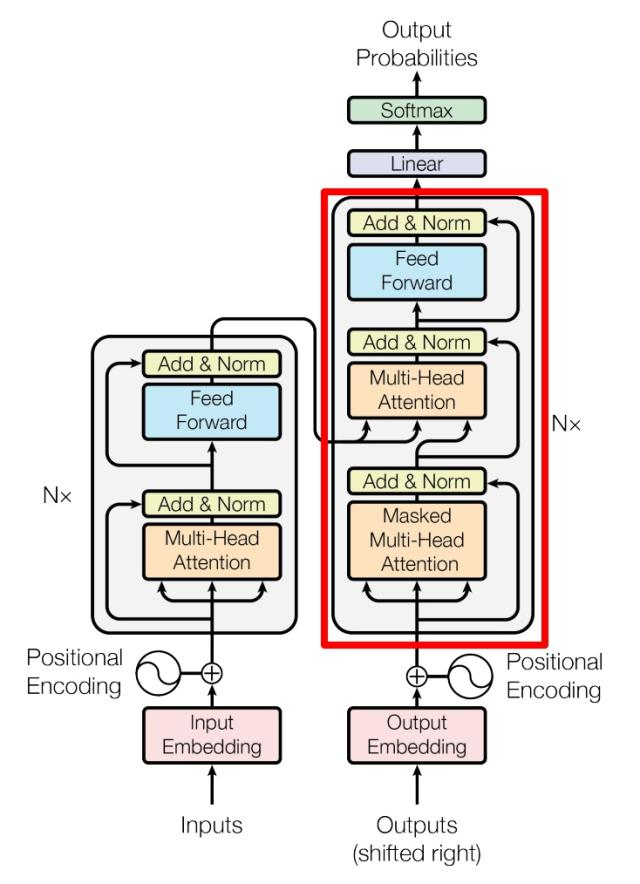
接下来看向结构的另一边。
红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
-
包含两个 Multi-Head Attention 层。
-
第一个 Multi-Head Attention 层采用了 Masked 操作。
-
第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
-
最后有一个 Softmax 层计算输出(比如下一个词的预测等等)。
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作。这是因为Sequence的分析是有序的。例如在翻译任务中,单词往往是顺序翻译的,即翻译完第 $i$ 个单词,才可以翻译第 $i+1$ 个单词。
在这之后在经过一层 Multi-Head Attention 利用全局信息,避免局限性;最后用 Softmax 进行输出。
这就是Transformer的结构了。
cross-attention
Transformer 的原始模型里使用的是 self-attention,毕竟他还是依据同一段信息的上下文来进行推理;但是在多模态的应用方面要使用 cross-attention。
Cross-Attention是两端的注意力机制,然后合起来,输入不同。Cross-attention将两个相同维度的嵌入序列不对称地组合在一起,而其中一个序列用作查询Q输入,而另一个序列用作键K和值V输入。
- Transformer架构中混合两种不同嵌入序列的注意力机制
- 两个序列必须具有相同的维度
- 两个序列可以是不同的模式形态(如:文本、声音、图像)
- 一个序列作为输入的 $Q$,定义了输出的序列长度,另一个序列提供输入的 $K$ & $V$
也就是说Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列,也就是所谓的输入不同,但是除此之外,基本一致。
也就是: \(\mathrm{softmax}((W_Q S_2)(W_K S_1))W_VS_1\)
DETR
毕竟是为了CV学这个的,那必须提到一下DETR。DETR就是DEtection TRansformer的缩写。
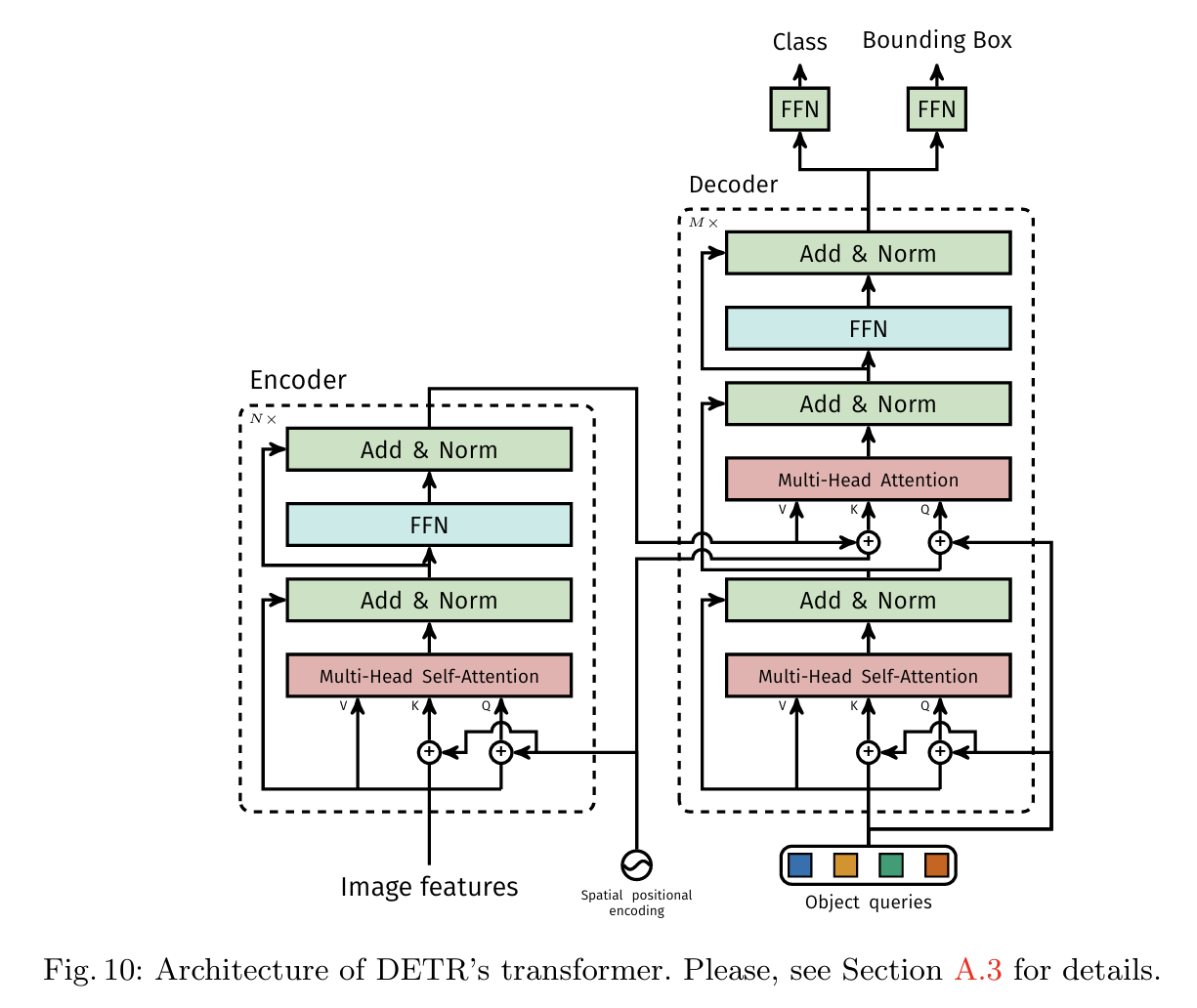
非常相像的结构。其实感觉DETR和transformer本尊的区别可能就是编码方式的不同。spatial positional encoding是作者自己提出的二维空间位置编码方法,该位置编码分别被加入到了encoder的self attention和decoder的cross attention,同时object queries也被加入到了decoder的两个attention中。而原版的Transformer将位置编码加到了input和output embedding中。
DETR的思路和传统的目标检测的本质思路有相似之处,但表现方式很不一样。传统的方法比如Anchor-based方法本质上是对预定义的密集anchors进行类别的分类和边框系数的回归。DETR则是将目标检测视为一个集合预测问题(集合和anchors的作用类似)。由于Transformer本质上是一个序列转换的作用,因此,可以将DETR视为一个从图像序列到一个集合序列的转换过程。该集合实际上就是一个可学习的位置编码(文章中也称为object queries或者output positional encoding,代码中叫作query_embed)。
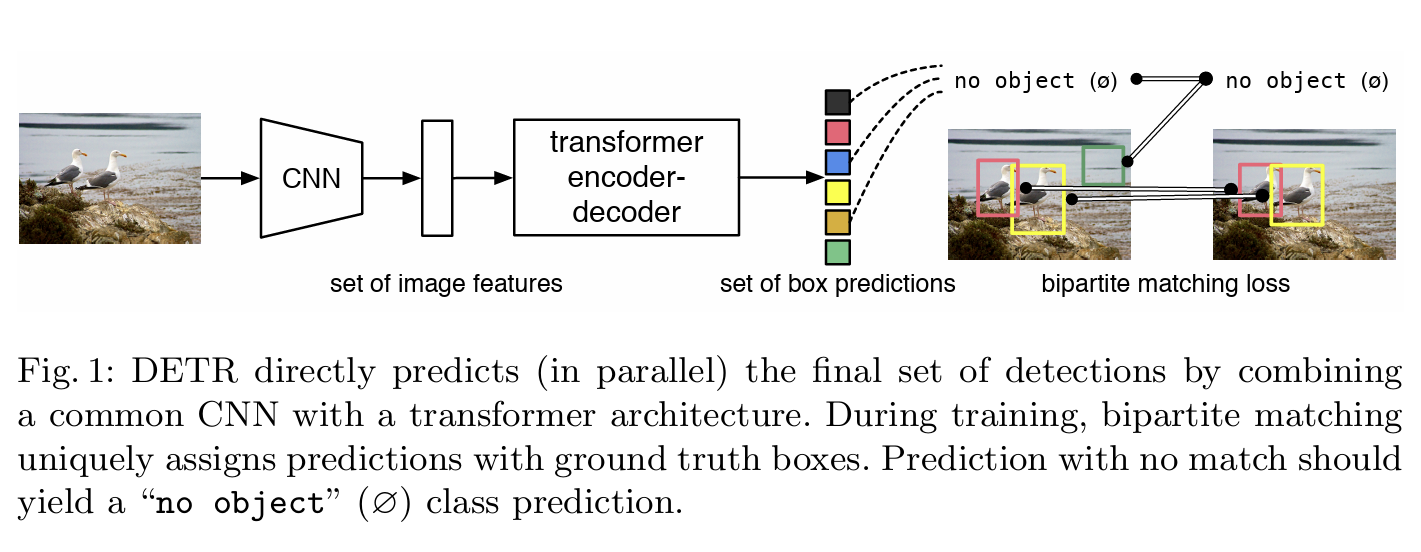
在预测过程中,DETR 预测了一组固定大小的 N = 100 个边界框。为了把预测框和ground truth匹配,DETR 将 ground-truth 也扩展成 N = 100 个检测框,同时使用了一个额外的特殊类标签 $\phi$ 来表示在未检测到任何对象,或者认为是背景类别的框。这样预测和真实都是两个 100 个元素的集合了。这时候采用匈牙利算法进行二分图匹配,即对预测集合和真实集合的元素进行一一对应,使得匹配损失最小。