
前情提要
这篇笔记是由 2024CVPR DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes 伸展出去的,看到什么就记什么了。
NeRF
NeRF,全称为“Neural Radiance Fields”,是一种基于神经网络的三维重建技术。它主要用于从一组二维图像中生成高质量的三维场景,特别适用于场景的渲染和建模。NeRF的主要创新在于它通过一个神经网络来表示整个三维场景,并且能够生成非常逼真的视角变化效果。
NeRF的基本原理
NeRF通过一个深度神经网络(通常是一个多层感知器,MLP)来学习场景的辐射场。具体来说,NeRF接受一个空间位置(三维坐标)和一个视角(方向)作为输入,并输出该位置在该视角下的颜色和密度。通过对多个视角下的场景进行训练,NeRF可以推测出在新视角下的场景外观。
工作流程
- 输入数据:首先,用户提供一组拍摄自不同角度的二维图像,并且知道每张图像对应的摄像机参数(如位置和方向)。
- 网络训练:NeRF使用这些图像及其对应的摄像机参数来训练一个神经网络,使其能够为任意给定的空间点和视角预测颜色和密度。
- 视图合成:训练完成后,NeRF可以生成任意新视角下的图像,甚至可以对场景进行导航和自由探索。
NeRF 的主要工作
[CVPR 2023] [LocalRF] Progressively optimized local radiance fields for robust view synthesis
之前的问题:First, most existing radiance field reconstruction approaches rely on accurate pre-estimated camera poses from Structurefrom- Motion algorithms, which frequently fail on in-thewild videos. Second, using a single, global radiance field with finite representational capacity does not scale to longer trajectories in an unbounded scene.
看起来之前的工作中,相机准确位置的估计和重建工作是分开的,这个工作把两者放在了一起。论文提出了一种渐进式的方法,联合估计相机姿态和辐射场。
这篇论文的核心内容是分块,文章用了slam的思想,边运动边重建,并将场景划分为 若干个小的TensorRT块。每个块单独优化辐射场和像机pose。
解决的问题:In this setting, we are faced with two main challenges: estimating accurate camera trajectory of a long path and reconstructing the large-scale radiance fields of scenes.
模型结构
-
局部辐射场(Local Radiance Fields):
- 为了处理大规模无界场景,论文提出了动态分配局部辐射场的方法。这些局部辐射场被训练以覆盖视频序列中特定时间窗口内的帧。
- 每个局部辐射场负责重建场景的一部分,并且具有自己的收缩中心,允许高分辨率空间跟随相机轨迹。

-
TensoRF:
- 论文选择了TensoRF作为基础表示,因为它在质量和训练速度方面表现良好。
- TensoRF通过一个分解的4D张量来建模场景,将3D位置映射到相应的体积密度和视角依赖的颜色。
-
空间参数化:
- 论文采用了一种类似于Mip-NeRF360的收缩方法,将每个点映射到一个统一的[-2, 2]空间,以适应任意长度的相机轨迹。
训练方法
- 渐进式优化:
- 为了提高鲁棒性,论文采用了渐进式优化方案,通过一个时间窗口逐步处理输入视频序列,并增量更新辐射场和相机姿态。
- 这种方法确保新帧被添加到之前结构的已收敛解中,有效防止陷入较差的局部最小值。
- 局部性引入:
- 通过在估计的相机姿态轨迹超出当前辐射场的未收缩空间时动态创建新的辐射场,引入了局部性。
- 每个辐射场仅使用视频的一个子集进行监督,提高了鲁棒性。
- 损失函数:
- 除了使用输入帧的颜色作为监督外,论文还添加了单目深度和相邻帧之间的光流作为损失,以提高优化稳定性。
- 优化调度:
- 使用Adam优化器进行参数优化,初始学习率和损失权重根据论文中的描述进行设置。
- 通过逐步添加监督帧和调整学习率和损失权重,实现了对整个视频序列的处理。
[CVPR 2022] Block-NeRF: Scalable Large Scene Neural View Synthesis
这也是一个分块的 NeRF,比前者更早,尺度更大一些。
以下摘自 NeRF神经辐射场学习笔记(八)— Block-NeRF论文创新点解读-CSDN博客
Block-NeRF是一种NeRF新的延伸,用来表示大规模环境。在渲染城市规模的场景时,将城市场景分为多个模块(Blocks),并且将NeRF也单独分配给每个block进行渲染,在预测时动态地呈现和组合这些NeRFs。这种分解(decomposition)的过程将渲染时间与场景大小解耦(decouples),即分隔开两者之间的必然联系,使渲染能够扩展到任意大的环境,并允许对环境进行逐块更新(per-block updates ofthe environment)。
针对以下目的——使NERF对不同环境条件下数月捕获的城市场景的数据具有鲁棒性,Block-NeRF的一些建设性的改进:
- 外观嵌入(appearance embeddings)和通过学习的位姿优化(learned pose refinement):应对采集数据时的环境变化和位姿错误;(environmental changes and pose errors) 对于单个NeRF的可控曝光(controllable exposure):通过添加曝光条件来提供在预测时修改曝光的能力;
- 提出了一种在相邻NeRFs之间的配准方法(aligning appearance between adjacent NeRFs):通过优化不同Block-NeRF的外观嵌入信息以匹配光照条件,并使用基于每个块神经网络到新视图的距离计算的插值权重(use interpolation weights computed based on each Block-NeRF’s distance to the novel view),使整个场景实现视觉上的配准。
[CVPR 2022] Mega-NeRF:Scalable Construction of Large-Scale NeRFs for Virtual Fly-Throughs
我们使用神经辐射场 (nerf) 从大规模的视觉捕获中构建交互式3D环境,这些捕获跨越建筑物,甚至是主要从无人机收集的多个城市街区。与单个对象场景 (传统上对nerf进行评估) 相反,我们的规模提出了多个挑战,包括 (1) 需要对具有不同照明条件的数千个图像进行建模,每个图像仅捕获场景的一小部分,(2) 令人望而却步的大模型容量,使其无法在单个GPU上进行训练,并且 (3) 快速渲染将实现交互式飞行的重大挑战。为了解决这些挑战,我们首先分析大规模场景的可见性统计信息,从而激发稀疏的网络结构,其中参数专门用于场景的不同区域。我们介绍了一种用于数据并行性的简单几何聚类算法,该算法将训练图像 (或更确切地说是像素) 划分为可以并行训练的不同NeRF子模块。我们在现有数据集 (Quad 6k和UrbanScene3D) 以及我们自己的无人机镜头上评估我们的方法,将训练速度提高3倍,将PSNR提高12%。我们还在mega-NeRF之上评估了最近的NeRF快速渲染器,并介绍了一种利用时间一致性的新颖方法。我们的技术比传统的NeRF渲染实现了40倍的加速,同时保持在0.8 db以内的PSNR质量,超过了现有快速渲染器的保真度。
IDEA
- 关键见解是将训练像素几何划分为与每个子模块相关的小数据分片,这对于有效的训练和高精度至关重要。
- Mega-NeRF采用了前景/背景划分,我们进一步限制了前景和采样范围。
- Mega-NeRF利用几何可见性推理来分解训练像素的集合,从而允许从遥远的相机捕获的像素仍然影响空间单元。
技术解析
Mega-NeRF的核心是优化NeRF模型以提高效率和渲染速度。它采用了以下关键技术:
-
分层结构:Mega-NeRF引入了一个多级表示的层次结构,使得模型能够更有效地处理复杂的场景。这种设计允许近处的细节在低层级被精确捕捉,而远处的大规模结构则在高层级被编码。
-
稀疏采样:传统NeRF采用均匀采样,但Mega-NeRF利用动态采样策略,针对每个像素仅选择关键点进行计算,减少了不必要的计算量,提升了性能。
-
并行计算:该项目充分利用GPU的并行计算能力,优化了渲染过程,实现了高分辨率下的实时交互。
-
缓存策略:通过智能缓存最近的查询结果,Mega-NeRF能够减少重复计算,进一步加快渲染速度。
摘自 Mega-Nerf学习笔记-CSDN博客 探索Mega-NeRF: 实时的高分辨率神经辐射场建模-CSDN博客
[CVPR 2023] Neural Fields meet Explicit Geometric Representationsfor Inverse Rendering of Urban Scenes
这个看起来可以获得材质,然后重新布光渲染,很酷
这篇论文介绍了一种名为Fegr(Neural Fields meet Explicit Geometric Representations)的新方法,它用于从拍摄的图像中重建城市场景的几何结构和恢复场景的内在属性,如材质属性和照明信息。Fegr结合了神经辐射场(NeRF)和显式网格表示的优点,能够处理复杂的光照效果,如投射阴影和镜面高光。
主要贡献和特点包括:
- 混合渲染管线:Fegr使用神经场来估计初级光线(通过体积渲染),并使用从神经场重建的显式网格来模拟产生高阶光照效果(如投射阴影)的次级光线。
- HDR照明和材质属性建模:Fegr能够模拟场景的HDR属性,使其适用于如重光照和虚拟物体插入等下游应用。
- 高效的光线追踪:通过使用优化的光线追踪库(如OptiX),Fegr能够高效地计算次级光线,实现实时渲染。
- 端到端优化:Fegr通过最小化观察视图的重建误差,并使用多个正则化项来约束高度欠定的问题,从而实现端到端的优化。
- 数据集和实验:论文使用多个城市户外数据集评估Fegr,并与现有的技术进行了比较,展示了其在不同挑战性数据集上的优势。
- 应用示例:论文展示了Fegr在重光照和虚拟物体插入等应用中的潜在用途,并通过用户研究验证了其生成结果的逼真度。
- 局限性:尽管Fegr在神经渲染方面取得了重要进展,但它也有局限性,如依赖于手动设计的先验来定义正则化项,以及目前仅限于静态场景。
总体而言,Fegr通过结合神经场的高分辨率细节和显式网格的高效渲染,为城市场景的逆向渲染提供了一种有效的解决方案。
模型结构的关键组成部分如下:
- 神经场(Neural Field):
- 神经场用于表示场景的内在属性,包括几何形状、法线向量、基础颜色(Base Color)和材质属性(包括粗糙度和金属度)。
- 神经场由多个多层感知器(MLP)组成,分别用于预测场景中每个3D位置的Signed Distance(SD)值、法线向量、基础颜色和材质属性。
- 显式网格(Explicit Mesh):
- 从神经场的Signed Distance Field(SDF)中提取显式网格,用于高效地进行光线追踪和渲染次级光线,如投射阴影和镜面高光。
- 使用Marching Cubes算法从SDF中提取网格。
- HDR环境光照(HDR Lighting):
- 通过一个MLP网络表示HDR环境光照,该网络将方向向量映射到高动态范围(HDR)光照强度值。
- HDR环境光照允许进行场景操作,如重光照和虚拟物体插入。
- 混合延迟渲染管线(Hybrid Deferred Rendering Pipeline):
- 体积渲染(Volume Rendering):使用神经场进行体积渲染,生成G-buffer,包含每个像素的表面法线、基础颜色、材质参数和深度信息。
- 光线追踪(Ray Tracing):使用从SDF提取的显式网格,通过光线追踪计算次级光线,实现对复杂光照效果的渲染。
- 优化方案(Optimization Scheme):
- 通过最小化重建误差和多个正则化项来优化神经场景表示。
- 使用L1重建损失来最小化输入图像和使用混合渲染器渲染的视图之间的差异。
- 引入辅助辐射场(Auxiliary Radiance Field)和深度损失(Depth Loss)来提供几何形状的辅助监督。
- 通过法线正则化(Normal Regularization)和光照正则化(Shading Regularization)来约束问题的欠定性。
- 损失函数(Loss Function):
- 重建损失(Reconstruction Loss):用于优化神经场景表示,使其能够根据输入图像重建场景。
- 几何监督损失(Geometry Supervision Loss):包括辐射度损失(Radiance Loss)和深度损失(Depth Loss),用于约束几何形状。
- 法线正则化损失(Normal Regularization Loss)*和*光照正则化损失(Shading Regularization Loss):用于确保法线向量和光照效果的一致性。
- 天空掩码损失(Sky Mask Loss)*和*平滑损失(Smoothness Loss):用于优化场景表示的其他正则化项。
- 实现细节(Implementation Details):
- 神经场和HDR环境光照的网络结构、训练过程中的采样策略、以及用于光线追踪的OptiX库的实现细节。
[ICPL 2023] Switch-NeRF: Learning Scene Decomposition with Mixture of Experts for Large-scale Neural Radiance Fields
这篇论文介绍了一种名为Switch-NeRF的新型神经辐射场(NeRF)方法,它通过学习场景分解来有效地重建大规模场景。Switch-NeRF的核心创新在于使用了一个可学习的门控网络(gating network),该网络将3D点分派给不同的NeRF子网络进行处理。这种方法允许端到端地学习场景分解和NeRF,而不需要人为设计的场景分解规则。
主要贡献和特点包括:
- 端到端学习:Switch-NeRF将场景分解和NeRF的优化过程集成到一个统一的框架中,使得网络可以通过反向传播直接学习场景分解。
- 稀疏门控混合专家(Sparsely Gated Mixture of Experts, MoE):Switch-NeRF采用了MoE的设计,其中门控网络动态选择并激活最适合处理每个3D点的子网络。
- 高效的网络设计和实现:论文提出了一种高效的网络架构和实现策略,以确保在保持高保真度场景重建的同时,计算效率也得到优化。
模型结构:
- 门控网络(Gating Network):
- 门控网络负责为每个3D点选择最合适的NeRF子网络进行处理。它是一个可训练的神经网络,输出一组门控值,表示每个点被分派到不同子网络的概率。
- 门控网络采用Softmax函数进行归一化,并通过Top-k操作(通常是Top-1)选择一个最有可能的子网络来处理输入点。
- 门控网络的设计允许与NeRF子网络一起端到端训练,无需人为干预。
- NeRF子网络(NeRF Experts):
- 每个NeRF子网络是一个深层的多层感知器(MLP),专门处理由门控网络分派的3D点。
- 子网络输出选定点的特征向量,这些特征随后用于预测空间中的密度(σ)和颜色(c)。
- 子网络之间相互独立,但通过门控网络的协调作用,共同参与整个场景的重建。
- 统一的头部网络(Unified Head):
- 头部网络是一个共享网络,用于整合来自不同子网络的输出,并进行最终的密度和颜色预测。
- 它接收来自选定子网络的输出特征,结合视点方向和外观嵌入(appearance embedding),预测每个3D点的颜色和密度。
- 容量因子和全分派(Capacity Factor and Full Dispatch):
- 为了在训练中高效地分派3D点,Switch-NeRF引入了容量因子,限制每个子网络处理的样本点数量,以保持计算和内存使用的平衡。
- 测试时,Switch-NeRF采用全分派策略,确保所有3D点都被处理,从而提高测试精度。
- 体积渲染和损失函数(Volume Rendering and Losses):
- Switch-NeRF遵循传统的NeRF体积渲染流程,通过沿相机射线采样并预测颜色和密度,合成像素的颜色。
- 模型的训练使用渲染损失(rendering loss)作为主要的监督信号,通过比较网络渲染的图像和真实图像之间的差异来优化网络参数。
- 辅助损失(Auxiliary Loss):
- 为了解决门控网络可能偏向于某些子网络的问题,Switch-NeRF引入了辅助损失,以平衡不同子网络的训练和利用。
3D Gaussian Splatting
在 3DGS 中,3D高斯函数被用来表示场景中的体积元素,这些高斯函数在空间中定义了位置、协方差矩阵和不透明度。也有一些体素的意思了,感觉这种建模是一个一个球体(covariance的调整应该可以把它们变成椭球体) 拼合而成的,球越小,越细节。
[ACM Transactions on Graphics] 3D Gaussian Splatting for Real-Time Radiance Field Rendering
开山之作。
First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows realtime rendering.
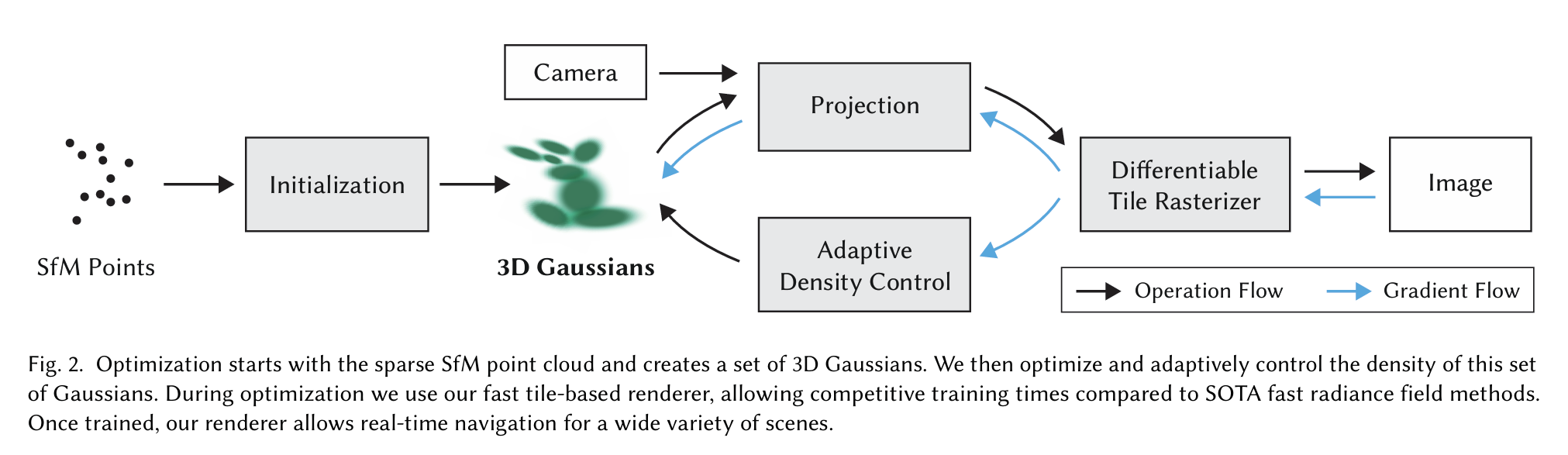
- 3D Gaussian表示:
- 场景通过一组3D高斯函数来表示,每个高斯函数定义了一个位置(均值),协方差矩阵(描述形状和方向的各向异性),以及不透明度。
- 这些高斯函数能够灵活地捕捉场景中的几何细节,并且可以通过优化过程调整其参数以匹配输入图像。
- 优化与训练:
- 通过从结构从运动(SfM)过程中获得的稀疏点云初始化3D高斯函数,然后通过迭代优化过程调整这些高斯的参数,以最小化渲染图像与真实图像之间的差异。
- 优化过程中,不仅包括位置和不透明度的调整,还包括协方差矩阵的各向异性调整,以确保高斯函数能够准确地表示场景中的几何结构。
- 实时可微分光栅化:
- 为了实现实时渲染,论文提出了一种基于瓦片的光栅化算法,该算法利用现代GPU的并行处理能力,通过分块排序和混合来高效地渲染3D高斯。
- 光栅化过程中,每个3D高斯被投影到2D平面上,并根据其不透明度和颜色值进行混合,以生成最终的像素颜色。
- 混合与排序:
- 在光栅化过程中,为了正确地混合重叠的高斯函数,需要对它们进行排序。论文使用基于深度的排序,确保了在混合过程中保持正确的可见性顺序。
- 通过使用快速的GPU排序算法(如Radix排序),可以高效地处理大量的高斯函数,从而实现实时渲染。
- 正则化与损失函数:
- 为了确保优化过程的稳定性和高斯函数的质量,论文引入了多种正则化项,包括梯度正则化、各向异性协方差正则化和不透明度正则化。
- 使用L1损失函数和结构相似性(SSIM)损失函数来衡量渲染图像与真实图像之间的差异,并将其作为优化的目标函数。
- 自适应密度控制:
- 在优化过程中,论文提出了一种自适应控制高斯密度的方法,通过添加和移除高斯函数来改善场景的表示。
- 在某些情况下,例如当高斯函数覆盖了过大的区域或在场景中存在未被充分重建的区域时,会触发高斯函数的分裂或克隆,以提高场景重建的精度。
[CVPR 2024] 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
3D上增加的这一D想必就是时间吧。
用于实时渲染动态场景,特别是针对自动驾驶场景的动态背景和多个动态对象。该方法的核心是将场景分解为静态背景和动态对象,分别使用增量式静态3D高斯和复合动态高斯图来重建,并通过高斯光栅化进行全局渲染,以捕捉现实世界中的遮挡关系。
“4D Gaussian Splatting” 方法是一种用于实时渲染动态场景的技术,它通过将场景分解为静态背景和动态对象,并分别对它们进行建模和渲染。以下是该方法的详细原理:
- 增量式静态3D高斯(Incremental Static 3D Gaussians):
- 该方法首先将场景的静态背景通过增量式的方式用3D高斯函数进行建模。这些高斯函数由位置、协方差矩阵和不透明度参数化,能够灵活地捕捉场景的几何细节。
- 通过利用车辆运动引入的透视变化和时间关系,逐步构建静态背景。使用来自激光雷达(LiDAR)的先验信息初始化高斯模型,提供精确的几何结构和全景一致性。
- 复合动态高斯图(Composite Dynamic Gaussian Graph):
- 对于场景中的动态对象,如行驶中的车辆或移动的行人,该方法使用一个复合动态高斯图来单独重建每个对象,并动态地将它们集成到整个场景中。
- 动态对象通过数据集提供的边界框或3D对象检测器和跟踪器预测的结果来识别。然后,为每个动态对象实例化一组动态高斯,并共同优化所有与这些对象相关的参数。
- 高斯变形场网络(Gaussian Deformation Field Network):
- 该网络包含一个空间-时间结构编码器和一个多头高斯变形解码器。编码器负责编码3D高斯的空间和时间特征,而解码器则预测每个3D高斯的变形。
- 通过这个网络,可以在新的时间戳上预测高斯变形,从而实现对动态对象的准确建模。
- 全局渲染(Global Rendering):
- 使用可微分的3D高斯光栅化技术,将全局复合3D高斯投影到2D图像平面上。这个过程涉及到对每个像素进行颜色和不透明度的累积计算,以生成最终的渲染图像。
- 优化过程:
- 通过最小化渲染图像与真实图像之间的差异来优化网络参数。使用L1损失函数和结构相似性(SSIM)损失函数来衡量渲染图像的质量。
- 在训练过程中,还引入了辅助损失函数来平衡不同高斯的利用,确保网络能够均匀地学习场景的各个部分。
[CVPR 2024] Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
这一篇在机器之心有中文讲解:CVPR 2024满分论文:浙大提出基于可变形三维高斯的高质量单目动态重建新方法 - 知乎 (zhihu.com)
以下为从这篇文章的转载
单目动态场景(Monocular Dynamic Scene)是指使用单眼摄像头观察并分析的动态环境,其中场景中的物体可以自由移动。单目动态场景重建对于理解环境中的动态变化、预测物体运动轨迹以及动态数字资产生成等任务至关重要。
随着以神经辐射场(Neural Radiance Field, NeRF)为代表的神经渲染的兴起,越来越多的工作开始使用隐式表征(implicit representation)进行动态场景的三维重建。尽管基于 NeRF 的一些代表工作,如 D-NeRF,Nerfies,K-planes 等已经取得了令人满意的渲染质量,他们仍然距离真正的照片级真实渲染(photo-realistic rendering)存在一定的距离。
来自浙江大学、字节跳动的研究团队认为,上述问题的根本原因在于基于光线投射(ray casting)的 NeRF pipeline 通过逆向映射(backward-flow)将观测空间(observation space)映射到规范空间(canonical space)无法实现准确且干净的映射。逆向映射并不利于可学习结构的收敛,使得目前的方法在 D-NeRF 数据集上只能取得 30 + 级别的 PSNR 渲染指标。
为了解决这一问题,该研究团队提出了一种基于光栅化(rasterization)的单目动态场景建模 pipeline,首次将变形场(Deformation Field)与 3D 高斯(3D Gaussian Splatting)结合,实现了高质量的重建与新视角渲染。研究论文《Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction》已被计算机视觉顶级国际学术会议 CVPR 2024 接收。值得一提的是,这是首个使用变形场将 3D 高斯拓展到单目动态场景的工作。
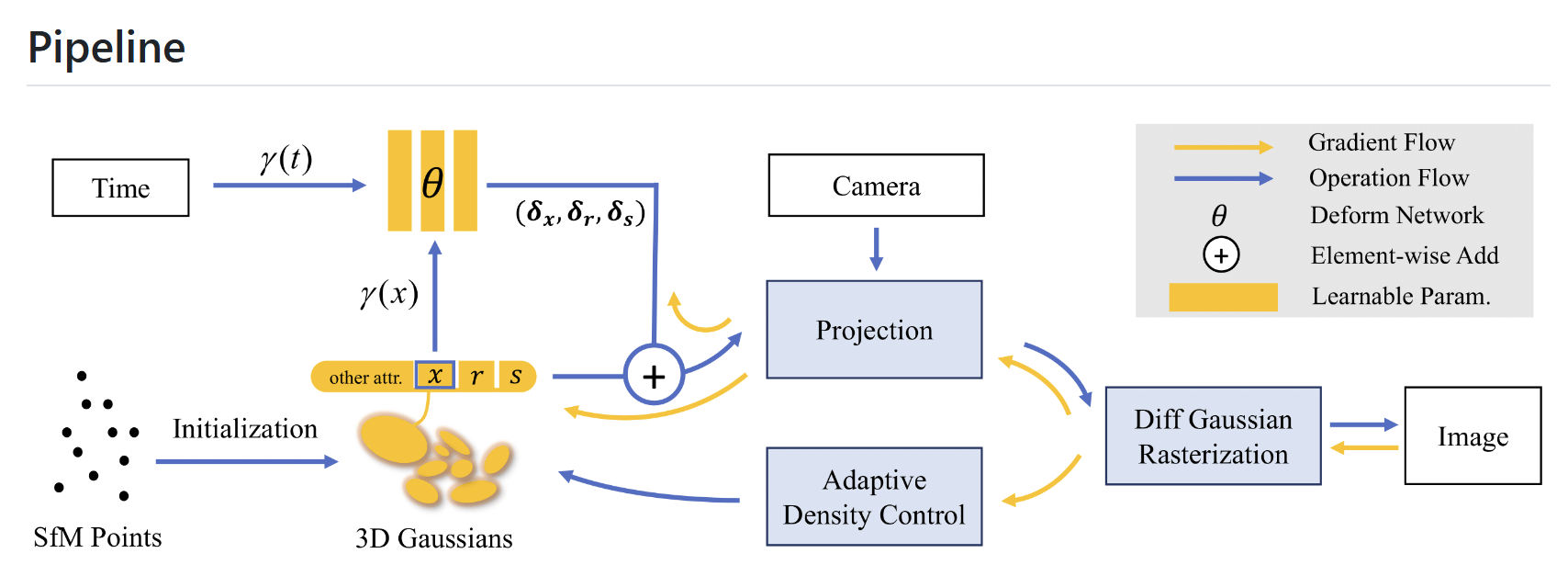
相关工作
动态场景重建一直以来是三维重建的热点问题。随着以 NeRF 为代表的神经渲染实现了高质量的渲染,动态重建领域涌现出了一系列以隐式表征作为基础的工作。D-NeRF 和 Nerfies 在 NeRF 光线投射 pipeline 的基础上引入了变形场,实现了稳健的动态场景重建。TiNeuVox,K-Planes 和 Hexplanes 在此基础上引入了网格结构,大大加速了模型的训练过程,渲染速度有一定的提高。然而这些方法都基于逆向映射,无法真正实现高质量的规范空间和变形场的解耦。
3D 高斯泼溅是一种基于光栅化的点云渲染 pipeline。其 CUDA 定制的可微高斯光栅化 pipeline 和创新的致密化使得 3D 高斯不仅实现了 SOTA 的渲染质量,还实现了实时渲染。Dynamic 3D 高斯首先将静态的 3D 高斯拓展到了动态领域。然而,其只能处理多目场景非常严重地制约了其应用于更通用的情况,如手机拍摄等单目场景。
研究思想
Deformable-GS 的核心在于将静态的 3D 高斯拓展到单目动态场景。每一个 3D 高斯携带位置,旋转,缩放,不透明度和 SH 系数用于图像层级的渲染。根据 3D 高斯 alpha-blend 的公式,不难发现,随时间变化的位置,以及控制高斯形状的旋转和缩放是决定动态 3D 高斯的决定性参数。然而,不同于传统的基于点云的渲染方法,3D 高斯在初始化之后,位置,透明度等参数会随着优化不断更新。这给动态高斯的学习增加了难度。
该研究创新性地提出了变形场与 3D 高斯联合优化的动态场景渲染框架。具体来说,该研究将 COLMAP 或随机点云初始化的 3D 高斯视作规范空间,随后通过变形场,以规范空间中 3D 高斯的坐标信息作为输入,预测每一个 3D 高斯随时间变化的位置和形状参数。利用变形场,该研究可以将规范空间的 3D 高斯变换到观测空间用于光栅化渲染。这一策略并不会影响 3D 高斯的可微光栅化 pipeline,经过其计算得到的梯度可以用于更新规范空间 3D 高斯的参数。
此外,引入变形场有利于动作幅度较大部分的高斯致密化。这是因为动作幅度较大的区域变形场的梯度也会相对较高,从而指导相应区域在致密化的过程中得到更精细的调控。即使规范空间 3D 高斯的数量和位置参数在初期也在不断更新,但实验结果表明,这种联合优化的策略可以最终得到稳健的收敛结果。大约经过 20000 轮迭代,规范空间的 3D 高斯的位置参数几乎不再变化。
研究团队发现真实场景的相机位姿往往不够准确,而动态场景更加剧了这一问题。这对于基于神经辐射场的结构来说并不会产生较大的影响,因为神经辐射场基于多层感知机(Multilayer Perceptron,MLP),是一个非常平滑的结构。但是 3D 高斯是基于点云的显式结构,略微不准确的相机位姿很难通过高斯泼溅得到较为稳健地矫正。
为了缓解这个问题,该研究创新地引入了退火平滑训练(Annealing Smooth Training,AST)。该训练机制旨在初期平滑 3D 高斯的学习,在后期增加渲染的细节。这一机制的引入不仅提高了渲染的质量,而且大幅度提高了时间插值任务的稳定性与平滑性。