
比较经典的端到端自动驾驶模型
古早时期:UniAD之前
这是来自 2023CVPR ReasonNet 的 related works End-to-end Autonomous Driving End-to-end autonomous driving in urban scenarios has become more studied recently thanks to the CARLA simulator and leaderboard [21]. Recent works mainly consist of reinforcement learning (RL) and imitation learning (IL) methods. The reinforcement Learning methods train the agents by constantly interacting with simulated environments and learning from these experiences. Latent DRL [54] first trains an embedding space as a latent representation of the environment observation, and then conducts reinforcement learning with the latent observation. Roach [66] utilizes an RL agent with privileged information of the environment to distill a model only with regular information (e.g. sensor) as the final agent. WOR [9] builds a model-based RL agent along with the world model and reward model. The final agent is distilled from the expert knowledge acquired from these pretrained models. Imitation learning methods aim at learning from an expert agent to bypass interacting with the environment. Early IL methods include CIL [17] and CILRS [18], which apply a conditional architecture with different network branches for different navigation commands. LBC [11] first trains an imitation learning agent with privileged information, which is then distilled into a model using sensor data. Transfuser [15, 47] designs a multi-modal transformer to fuse information between the front camera image and LiDAR data. LAV [10] exploits data of not only the ego vehicle but also surrounding vehicles for data augmentation by learning a viewpoint-invariant spatial intermediate representation. TCP [63] proposes a network with two branches which generates the control signal and waypoints respectively. An adaptive ensemble is applied to fuse the two output signals. InterFuser [51] uses a transformer to fuse and process multimodal multi-view sensors for comprehensive scene understanding.
CARLA
老朋友啦,用了一段时间了。闭环测试不可或缺的一环。
DRL
即“深度强化学习”,Deep Reinforcement Learning
Roach [End-to-End Urban Driving by Imitating a Reinforcement Learning Coach, ICCV 2021]
结合了RL和IL(模仿学习)。先用强化学习练出一个专家,再模仿学习这个专家。
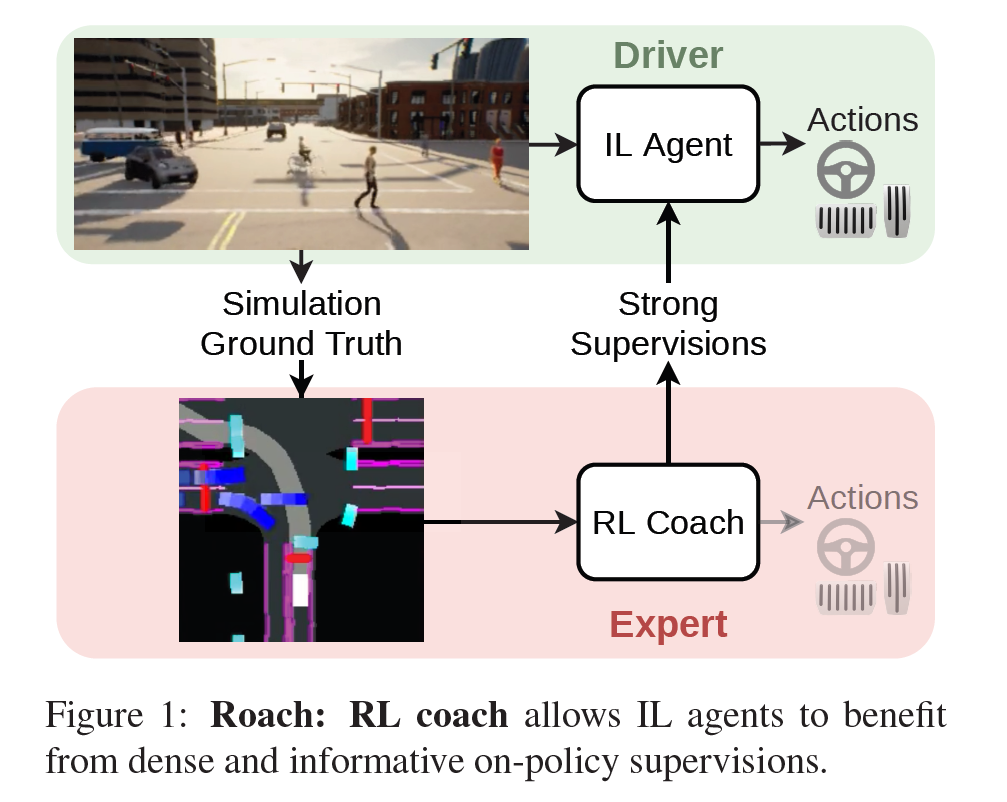
- 强化学习教练(RL Coach):
- Roach的核心是一个强化学习代理,它接受鸟瞰图(BEV)图像和测量向量作为输入,并输出连续的动作分布。
- 该代理由一个策略网络(πθ)和一个价值网络(Vφ)组成,其中策略网络将BEV图像和测量向量映射到动作分布,而价值网络估计一个标量值。
- 输入表示(Input Representation):
- 使用BEV语义分割图像作为输入,该图像包含可行驶区域、预期路线、车道边界、车辆、行人、交通灯和停止标志等信息。
- 输入还包括一个测量向量,包含车辆自身的状态信息,如转向、油门、刹车、挡位、横向和纵向速度。
- 输出表示(Output Representation):
- Roach直接预测动作分布,而不是预测航点计划。动作空间是二维的,包括转向和加速度。
- 动作分布采用Beta分布来描述,这允许输出动作的不确定性,并且Beta分布的支持是有限范围的,适合于驾驶任务。
- 训练(Training):
- 使用近端策略优化(PPO)算法来训练Roach的策略网络和价值网络。
- 采用最大熵损失和探索损失来鼓励策略网络进行探索,并使用广义优势估计来更新策略。
- 模仿学习代理(IL Agent):
- IL代理通过模仿Roach生成的监督信号来学习。这些信号包括动作分布、价值估计和潜在特征。
- 为了使IL代理从Roach生成的信息中受益,作者提出了针对每种监督信号的损失函数,包括动作分布损失、特征损失和价值损失。
- 网络架构(Network Architecture):
- Roach的网络架构包括用于编码BEV图像的卷积层和用于编码测量向量的全连接层。
- 输出的潜在特征被送入价值头和策略头,每个头都包含额外的全连接层。
- 数据收集与训练细节(Data Collection and Training Details):
- 从CARLA模拟器中收集数据,包括开环和闭环数据。
- 使用DAGGER算法进行闭环数据收集,以确保IL代理可以从Roach学习有效的策略。
WOR [Learning to drive from a world on rails, ICCV 2021]
论文的核心观点是通过一种基于模型的方法,从预先录制的驾驶日志中学习一个交互式的视觉驾驶策略。作者提出了一个“世界在轨道上”(world-on-rails)的假设,意味着代理(即自动驾驶车辆)及其行为不会影响环境。这个假设简化了学习问题。是一个简化的工作。
We thus make a simplifying assumption: The agent’s actions only affect its own state, and cannot directly influence the environment around it. In other words: the world is “on rails”. This naturally factorizes the world model into an agent-specific component that reacts to the agent’s commands, and a passively moving world. For the agent, we learn an action-conditional forward model. For the environment, we simply replay pre-recorded trajectories from the training data.
主要贡献包括:
- 提出了一种新的方法,通过学习世界模型和行动价值函数,训练一个能够在动态和反应性世界中表现良好的最终驾驶策略。
- 尽管基于“世界在轨道上”的假设,所提出的驾驶策略在CARLA排行榜上名列第一,使用的数据量是之前最先进方法的1/40。
- 该方法在ProcGen基准测试中的导航任务上,比现有的无模型强化学习技术样本效率高出一个数量级。
CIL [End-to-end Driving via Conditional Imitation Learning, ICRA 2018]
这篇比较精炼 End-to-end Driving via Conditional Imitation Learning 论文笔记-CSDN博客
自动驾驶的决策是有条件的,比如目的地的位置会决定我们在路口的转向,而不是当时周围情况。这时候需要设置一个“条件”。
CILRS [Exploring the limitations of behavior cloning for autonomous driving, ICCV 2019]
- 行为克隆的局限性:尽管行为克隆在训练环境中表现出色,但在处理动态对象和缺乏因果模型导致的泛化问题时存在局限性。此外,训练过程中的不稳定性也是一个问题。
- 数据集偏差和过拟合:行为克隆受到数据集偏差的影响,这可能导致在复杂条件下的泛化性能不佳。作者通过NoCrash基准测试证实了这一点。(Carla中no crash基准的起源)
- 因果混淆和惯性问题:行为克隆可能会因为数据集中的偏差而产生因果混淆,例如,当自我车辆停止时,模型可能会错误地将低速和不加速关联起来,导致在模仿策略中出现过度停车和难以重启的问题。
- 高方差问题:行为克隆模型对于训练数据的初始化和采样顺序非常敏感,这导致了高方差问题,即使在固定数据集上的不同训练运行中也可能出现显著的性能变化。
- 改进的行为克隆模型:作者提出了一个名为CILRS的改进模型,该模型使用更深的残差架构和速度预测来提高泛化性能。
LBC [Learning by cheating, 2019]
论文的核心观点是,通过将模仿学习过程分解为两个阶段,可以更有效地训练基于视觉的自动驾驶系统。
主要贡献和发现包括:
- 两阶段训练方法:首先训练一个拥有特权信息(如环境布局和所有交通参与者位置)的代理(称为”特权代理”),然后使用这个特权代理作为教师来训练一个没有特权信息、仅基于视觉的传感器运动代理。
- 特权代理的优势:特权代理可以直接观察环境的真实状态,从而专注于学习行为策略,而不需要学习如何从视觉输入中提取信息。
- 传感器运动代理:在第二阶段,传感器运动代理被训练来模仿特权代理的行为。该代理只使用来自合法传感器(实验中为单一前向摄像头)的视觉输入,不使用任何特权信息。
- 实验验证:作者使用这种方法训练了一个基于视觉的自动驾驶系统,并在CARLA基准测试和NoCrash基准测试中取得了显著的性能提升。该方法首次在CARLA基准测试的所有任务中实现了100%的成功率,并在NoCrash基准测试中创下了新纪录。
- 优势分析:这种分解方法的优势在于,特权代理可以在紧凑的中间表示上操作,学习更快,泛化更好。此外,特权代理可以提供比原始专家轨迹更强的监督,并且可以作为”白盒”,允许在任何状态下查询其内部状态,从而为传感器运动代理提供丰富的学习信号。
- 模拟与现实世界的转移:尽管训练过程在模拟器中进行,但最终的传感器运动策略不依赖于任何特权信息,也不局限于模拟器。它可以利用从模拟到现实世界的转移方法转移到物理世界。
- 实验设置和结果:作者在CARLA模拟器中进行了广泛的实验,验证了他们的方法在不同的天气条件和交通密度下的性能。实验结果表明,与之前的方法相比,新方法在遵守交通规则和减少事故方面有显著提升。
NEAT [Neural Attention Fields for End-to-End Autonomous Driving, ICCV 2021]
NEAT compresses the high-dimensional image features into a compact low-dimensional representation relevant to the query location (x, y, t), and provides interpretable attention maps as part of this process, without attention supervision.
- NEAT(NEural ATtention fields)提出:一种新的表示方法,通过端到端模仿学习模型,使自动驾驶车辆能够高效地理解场景的语义、空间和时间结构。
- 创新的表示方法:NEAT是一个连续函数,将鸟瞰视图(BEV)中的位置映射到航点和语义,使用中间的注意力图将高维2D图像特征迭代压缩成紧凑的表示形式。
- 选择性注意力:模型能够选择性地关注输入中与驾驶任务相关的区域,同时忽略不相关的信息,有效地将图像与BEV表示关联起来。
- 性能提升:在包含恶劣环境条件和具有挑战性场景的新评估设置中,NEAT超越了几个强基线,并与生成其训练数据的特权CARLA专家的驾驶得分相当。
- 可解释性:通过可视化带有NEAT中间表示的模型的注意力图,提供了改进的可解释性,有助于理解学习到的驾驶行为。
(没有仔细看)
Transfuser [Multimodal fusion transformer for end-to-end autonomous driving, CVPR 2021]
中文资料见此:【Transformer系列论文】TransFuser:端到端自动驾驶的多模态融合Transformer-CSDN博客
用transformer融合了LiDAR和摄像头信息。这种直接画出来网络结构的朴素图示现在是越来越少啦。
![]()
LAV [Learning from all vehicles, CVPR 2022]
也有一个比较主观的中文笔记 【论文阅读】CVPR2022: Learning from all vehicles - Kin_Zhang - 博客园 (cnblogs.com)
思路是学所有车,有点清奇。但是资源占用难道不会相当大吗?(后来在一些文章的吐槽里也确认了这一点)
问题场景
现实生活中,可能大家开车10000个小时 都不会遇到一次事故,但是我们一定见到过事故现场,由此启发:learning-based 也可以从log中的其他车辆行为学习到经验。
学习其他车辆的轨迹(也可以说是预测其他车辆轨迹)有助于我们自车的sample efficiency 而且也可以帮助我们see more interesting scenarios,同时也可以帮助我们避免碰撞;
但是问题是:对于其他车辆来说 是不像本身一样有所有传感器数据的,对于我们来说是一种 partial observation 所以需要一种 中间的表达态 来表示周围信息以代替传感器数据,然后所有可观测的车输出这样的数据 到网络中
TCP [Trajectory-guided control prediction for end-to-end autonomous driving, NeurIPS 2022]
ailab又一力作。对于端到端的驾驶任务,一般是从预测出轨迹,然后用控制器跟随;另一种则是直接预测controller输出;由两种方法启发,作者认为可以吸取各自优点,然后提出本文方法
TD;LR (太长不看版): 1.不同于以往的端到端模型,TCP有何特别? 模型设计着重点?NOT encoder!以往的端到端模型往往专注于输入信息的融合异己输入encoder部分的设计,而TCP专注于提取到feature之后的预测部分。
E2E AD 输出形式,轨迹or控制?平常的端到端模型采用轨迹+PID/控制信号中的一种,而TCP研究了这两种输出形式的各自特点和优劣,并将二者结合在一个统一框架中,达到取长补短优势互补的效果。
2.我们做了哪些具体工作? 我们通过大量实验分析了两种输出模型(轨迹预测+PID模型和直接输出控制模型)各自的特点。
针对模仿学习中,对于state-action pair独立同分布假设带来的问题,我们提出了推演预测未来多步控制信号的方案,赋予模型较短时序上的推理能力。
我们将轨迹预测分支和多步控制分支整合在一个框架中,并加入二者的交互,并根据先验方案灵活结合两分支输出,获得最佳的最终控制信号。
中文笔记:【论文阅读】Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Ba-CSDN博客 TCP:结合轨迹规划和控制预测的端到端自动驾驶框架_wayve 端到端-CSDN博客
- 集成方法:提出了一种集成方法,包含两个分支——轨迹规划分支和直接控制分支。轨迹分支预测未来轨迹,而控制分支采用新颖的多步预测方案,以推理当前动作和未来状态之间的关系。
- 相互指导:两个分支相互连接,控制分支在每个时间步骤接收来自轨迹分支的相应指导。
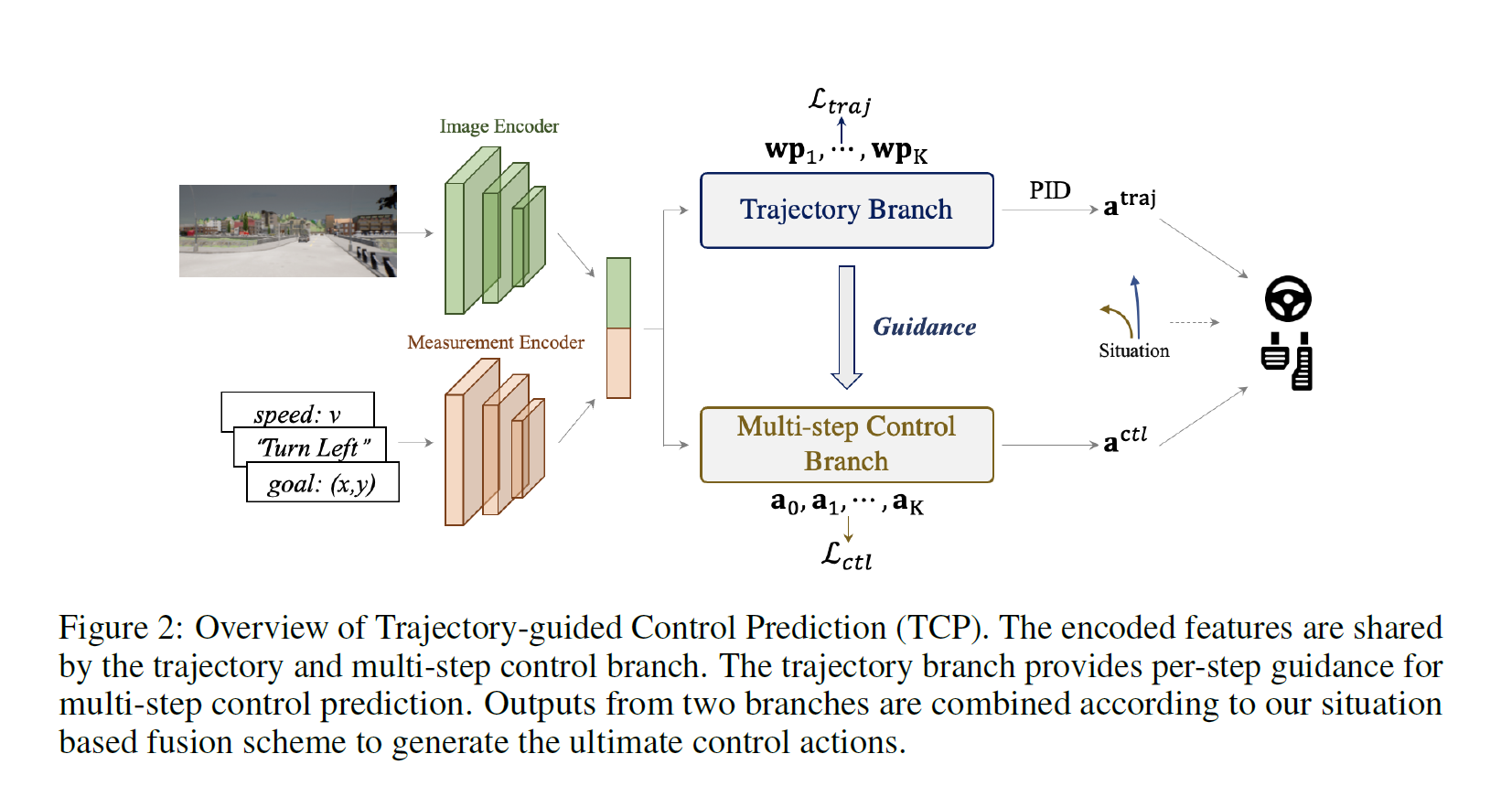
结构上,
-
输入编码阶段:
- 输入图像通过一个基于CNN的图像编码器(例如ResNet-34)来生成特征图FF。
- 导航信息g与当前车速v结合,形成一个测量输入m,然后通过一个基于MLP的测量编码器处理,输出测量特征
$j_{meas}$。
-
轨迹规划分支:
- 利用共享的特征,图像特征图F经过平均池化后与测量特征
$j_{meas}$拼接,形成$j_{traj}$。 $j_{traj}$输入到一个GRU单元中,以自回归方式逐个获得未来路径点,形成规划好的轨迹。
- 利用共享的特征,图像特征图F经过平均池化后与测量特征
-
多步控制分支:
- 此分支设计为输出多步控制动作πθmulti=(at,at+1,…,at+K)。
- 使用GRU作为时间模块,处理每一步的特征表示,考虑环境的动态变化和代理的交互。
- 引入轨迹引导的注意力机制,利用轨迹分支提供的信息,指导控制分支在每个未来时间步骤中关注输入图像的适当区域。
-
时间模块:
- 时间模块使用GRU实现,输入为当前控制特征和当前预测动作的组合。
- 更新后的隐藏状态
$h_{ctl}^{t+1}$包含有关环境和代理自身的动态信息。
-
轨迹引导的注意力:
- 通过学习注意力图来从编码的特征图中提取重要信息,以增强两个分支之间的一致性。
-
损失函数设计:
- 包含轨迹规划损失Ltraj,控制预测损失Lctl,以及辅助损失Laux。
- 轨迹规划损失使用L1距离和特征损失的组合。
- 控制预测损失使用Beta分布的KL散度,并同样应用特征损失。
-
输出融合:
- 根据情境基础的融合策略,将轨迹规划和控制预测的输出优势结合起来,形成最终的控制动作。
网络细节,在附录和正文里有简洁的说明:
- 相机尺寸是900x256,FOV直接拉满为100;
- K = 4 也就是选未来四步steps 的动作/轨迹进入
- Image Encoder 使用的是有预训练的 ResNet-34
- measurement encoder则是一个MLP [全文并未仔细说明具体几层;暂且认为和CILRS一致设置 也就是 根据输入的num 对应相应数量的linear到encoder里] → 128
- 各自encoder的输出 concat到一起 组成
$j_{traj}$→ 256
InterFuser [Safety-enhanced autonomous driving using interpretable sensor fusion transformer]
中文介绍 增强自动驾驶的安全性和可解释性:InterFuser大有可为 - OpenDILab - 博客园 (cnblogs.com)
我们认为导致以上安全问题的两个主要挑战是:
1)如何识别长尾分布的罕见不安全事件,如行人突然从路边出现,通过路口时遭遇意外车流(闯红灯等),这需要更好地理解多模态多视角传感器输入下的场景;
2)如何验证决策系统的安全性,换句话说,识别决策系统输出的意图和行为,以及识别故障情况和故障原因,这需要决策系统的可解释性。
从以上挑战出发,OpenDILab提出了InterFuser这一端到端自动驾驶策略,该策略基于Transformer进行多传感器融合,另外也使用了可解释性特征来增加自动驾驶的安全性,可以成功地缓解上述问题。
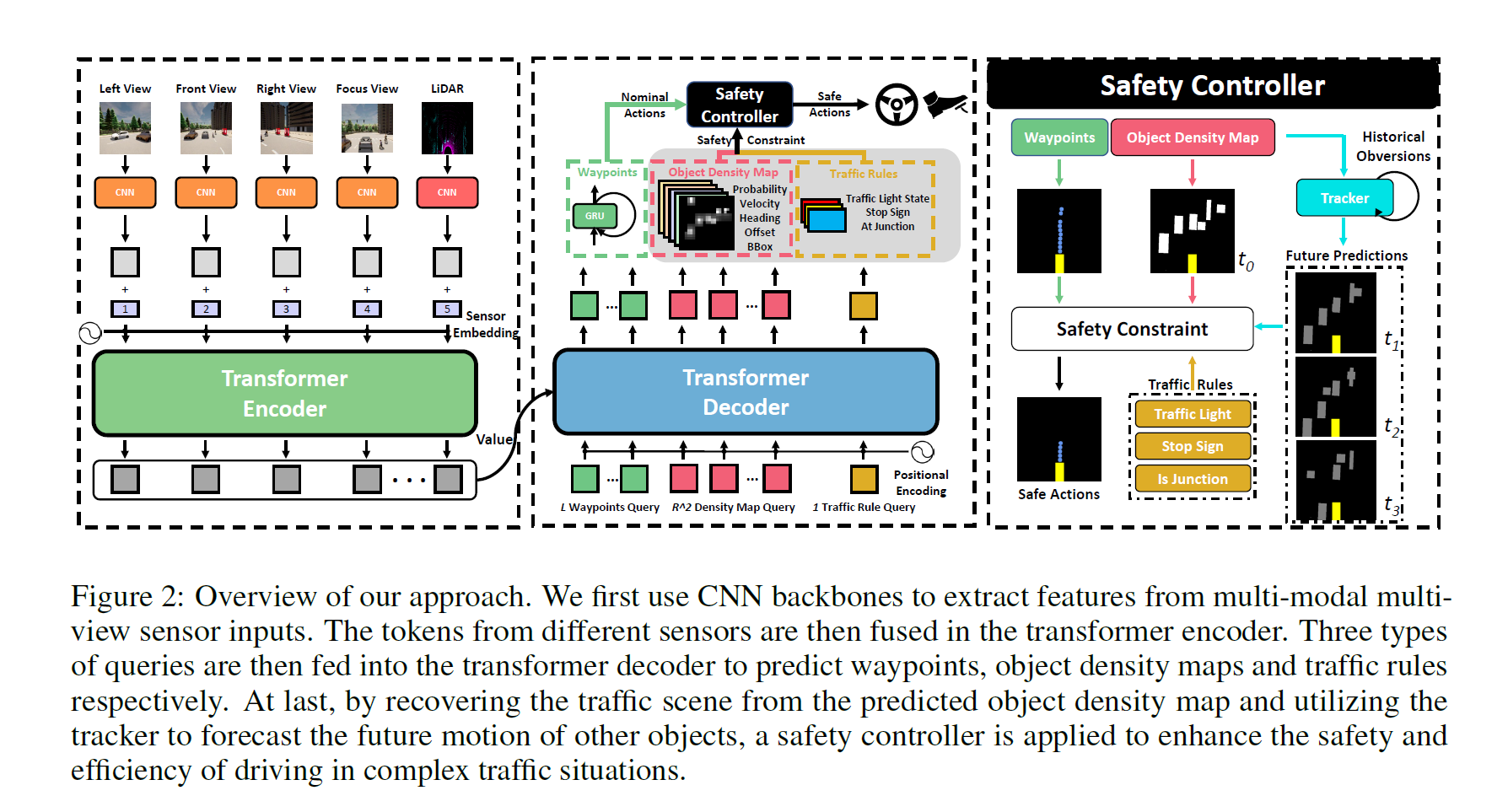
InterFuser 自动驾驶策略首先使用CNN网络从多模块多视角传感器输入中提取特征。这些特征会在Transformer Encoder中进行融合,融合过后的特征会作为后续Transformer Decoder模型的Value。
三种类型的query会被送入Transformer解码器以分别预测航点、物体密度图和交通信息。最后,我们通过从预测的物体密度图中恢复交通场景,利用Track技术获得场景中其他对象的未来预测位置等信息。
基于这些信息,应用一个安全控制器来确保在智能体复杂交通情况下的安全和高效驾驶。
本模型的结构使用CNN作为骨干网络,主要负责提取不同模态不同视角的图像特征。这些特征在加上位置编码和视图编码之后被送入Transformer的encoder网络进行特征融合。经过encoder网络融合之后的特征被视作values送入后续的Transformer的decoder网络。
在decoder网络中,我们设计了三种类型的queries:L个航点queries,R^2 个密度图queries和一个交通规则query。在每个解码器层中,我们采用这些query,通过注意机制来提取多模态和多视图特征中的空间信息。为了将decoder网络中提取得到的三种类型的特征转化为相应的具有实际意义的数值,我们在此之后应用了一些预测头。其中航点使用GRU网络进行预测,而密度图查询和交通规则查询使用MLP网络进行预测。
有了从Transformer decoder网络输出的航点和中间可解释特征(物体密度图和交通规则),我们就能把自动驾驶车辆的动作约束在安全集里。具体来说,我们使用PID控制器来获得两个低层次的动作。横向转向动作是车辆所需对准的方向。纵向加速动作的目的使自动驾驶车辆的速度接近期望速度 Vd 。 Vd 的确定需要考虑到周围的物体以确保安全,为此我们使用物体密度图完成此目标。
物体密度图M∈R×R×7的网格中的物体由物体存在概率、与网格中心的二维偏移量、二维边界框和运动方向描述。一旦满足以下条件之一,我们就认为该网格中存在一个物体。
1)如果物体在网格中的存在概率高于一个较高的阈值;
2)如果物体在网格中的存在概率是周围网格的局部最大值,并且大于一个较低的阈值。
除了物体的当前状态外,安全控制器还需要考虑它们的未来轨迹。我们首先设计一个跟踪器来监测和记录它们的历史动态。然后,我们通过用滑动平均法将其历史动态向后传播来预测其未来轨迹。
有了对自动驾驶车辆周围场景的恢复和对这些物体运动状态的未来预测,我们就可以得到自动驾驶车辆在时间步长t内可以行驶的最大安全距离,然后通过将其转化为线性规划问题来得到具有增强安全性的理想速度。
我们同时考虑了物体的形状,并考虑了车辆性能限制和车辆的动态约束。除了物体密度图,预测的交通信息也被用于安全驾驶。如果交通信号灯不是绿灯或前方有停车标志,自动驾驶车辆将执行紧急停车动作。
UniAD 之后
UniAD [Planning-oriented Autonomous Driving, CVPR 2023]
UniAD,四个 Transformer
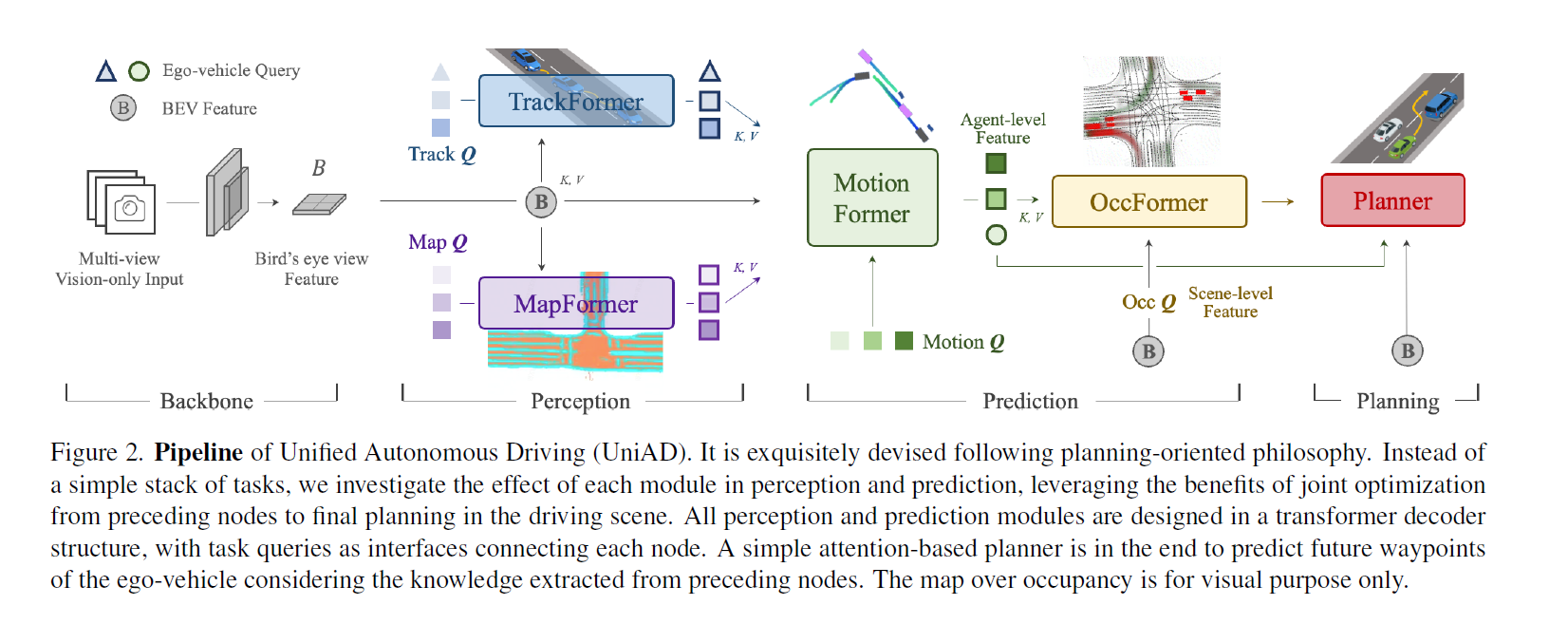
但是感觉还是比较模块化的,既然用了 BEVFormer(可以替换,但是也是 BEV encoder) 那其实也生成了高精地图和周围车辆信息这些东西了,后面的这些 Transformer 也是比较串行的一个接一个(除了 OccFormer 和 Planner)也接受了 Bev Feature Map 作为输入。
UniAD包含四个基于Transformer解码器的感知和预测模块,以及一个位于末端的规划模块。查询Q在连接管道中发挥作用,建模驾驶场景中实体的不同交互。具体来说,一系列多摄像头图像被输入特征提取器,得到的视角特征通过BEV编码器转换为统一的鸟瞰图(BEV)特征B。TrackFormer用于检测和跟踪代理;MapFormer表示道路元素并执行全景分割;MotionFormer捕捉代理和地图之间的交互并预测未来轨迹;OccFormer预测多步未来占用情况。最终,Planner利用来自MotionFormer的表达式强大的ego-vehicle查询进行规划预测,并避免碰撞。
-
TrackFormer: 具体来说,在每个时间步,初始化的检测查询负责检测首次感知到的新出现的目标,而跟踪查询则持续对前一帧中检测到的目标进行建模。
-
MapFormer:semantic map
这两个并行的transformer是什么结构?(得到中间表示再做embedding得到K, V?)
-
MotionFormer: MotionFormer predicts all agents’ multimodal future movements, i.e., top-k possible trajectories, in a scene-centric manner.
- OccFormer: Occupancy grid map is a discretized BEV representation where each cell holds a belief indicating whether it is occupied, and the occupancy prediction task is to discover how the grid map changes in the future. 但是这个 future occupancy map 是多 future 的?
- Planner: Planning without high-definition (HD) maps or predefined routes usually requires a high-level command to indicate the direction to go [11, 38]. Following this, we convert the raw navigation signals (i.e., turn left, turn right and keep forward) into three learnable embeddings, named command embeddings.
中文资料链接:https://zhuanlan.zhihu.com/p/632275644 https://blog.csdn.net/qq_34919792/article/details/131423998
VAD [VAD: Vectorized Scene Representation for Efficient Autonomous Driving, ICCV 2023]
向量化,重要 SOTA
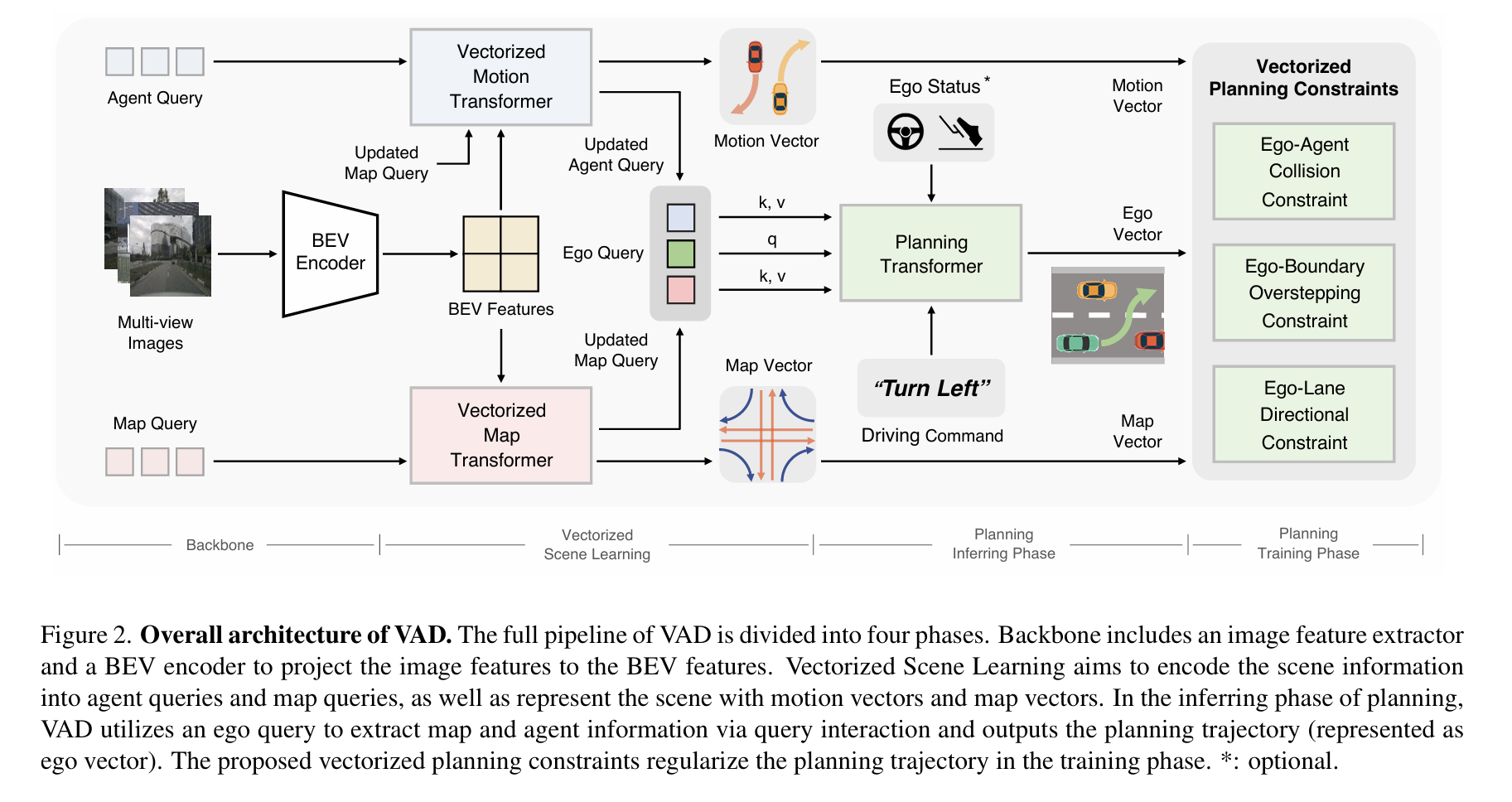
VAD的完整流程被分为四个阶段。主干部分包括一个图像特征提取器和一个BEV(鸟瞰视图)编码器,用于将图像特征投影到BEV特征上。矢量化场景学习的目标是将场景信息编码到代理查询和地图查询中,并使用运动向量和地图向量来表示场景。在规划的推理阶段,VAD利用自我查询通过查询交互提取地图和代理信息,并输出规划轨迹(表示为自我向量)。在训练阶段,提出的矢量化规划约束对规划轨迹进行规范化。
“这篇论文提出了一种名为VAD的自动驾驶场景表示向量化方法,旨在提高自动驾驶系统的规划性能和推理速度。以往的方法依赖于密集的栅格化场景表示(例如,代理占用和语义地图)来进行规划,这种方法计算密集且缺少实例级别的结构信息。本文提出了VAD,一种全面向量化的自动驾驶范式,将驾驶场景建模为完全向量化的表示。所提出的向量化范式具有两个显著优点。一方面,VAD利用向量化的代理运动和地图元素作为显式的实例级别规划约束,有效提高了规划安全性。另一方面,VAD比以往的端到端规划方法运行速度更快,通过摆脱计算密集的栅格化表示和手动设计的后处理步骤。“
OccNet [Scene as Occupancy, ICCV 2023]
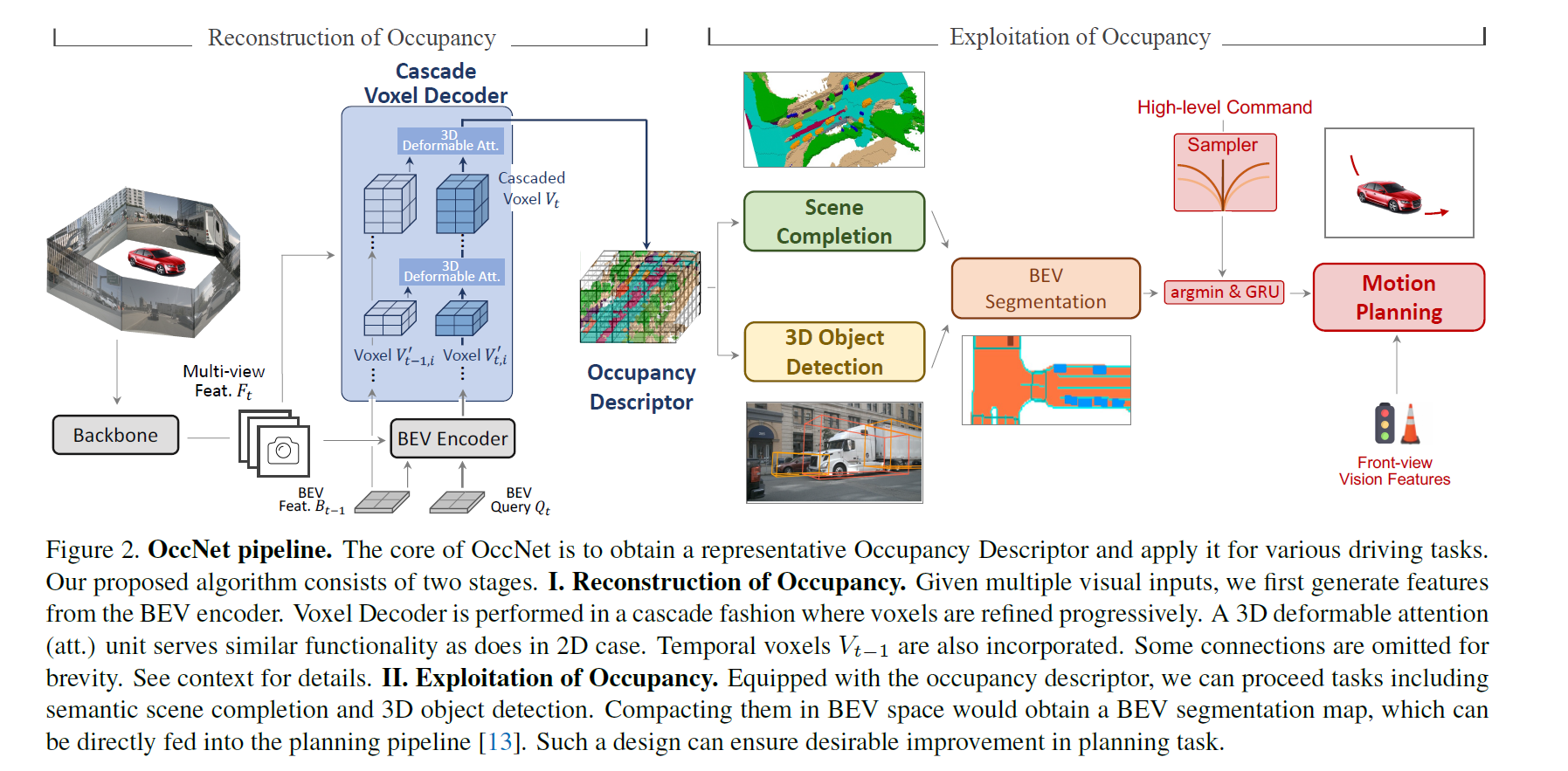
OccNet,使用体素代替传统空间表示(BEV + Bounding Box),重要工作
这篇论文提出了一个名为OccNet的新型自动驾驶感知框架,它基于多视图视觉中心流水线,利用级联和时间体素解码器重建三维占用(3D Occupancy)表示。这种表示通过将物理3D场景量化为具有每个单元语义标签的结构化网格图,与传统的边界框相比,能够捕获场景中关键障碍物的细粒度细节,从而有助于后续任务。
主要贡献和论文内容概括如下:
- 问题背景:人类驾驶员能够通过视觉系统轻松描述复杂的交通场景,这种精确感知能力对于驾驶员的规划至关重要。然而,对于以视觉为中心的自动驾驶系统来说,由于场景中实体的多样性,实现这种能力是具有挑战性的。
- OccNet框架:论文提出了OccNet,这是一个新颖的多视图视觉中心流水线,它通过级联体素解码器和时间线索来重建3D占用表示。OccNet的核心是通用的占用嵌入,能够描述3D物理世界,并广泛应用于包括检测、分割和规划在内的驾驶任务。
- OpenOcc基准:为了验证新表示的有效性和所提出算法的性能,论文提出了OpenOcc,这是基于nuScenes数据集构建的第一个密集且高质量的3D占用基准。OpenOcc包含超过14亿个3D占用单元的注释帧,覆盖了多种类别。
- 实验结果:实证实验表明,使用3D占用作为场景表示,在多个任务上都有显著的性能提升。例如,在运动规划任务中,碰撞率可以降低15%-58%,证明了该方法的优越性。
- 相关工作:论文还讨论了与3D目标检测、3D重建和渲染、以及语义场景完成等相关的研究工作,并指出了OccNet在这些领域的潜在影响。
- 方法论:详细介绍了OccNet的两个阶段:占用重建和占用利用。在占用重建阶段,OccNet从多视图特征中提取BEV(鸟瞰图)特征,并通过级联体素解码器逐步细化体素特征。在占用利用阶段,基于重建的占用描述符,可以部署各种驾驶任务。
- 效率和性能分析:论文对比了BEVNet、VoxelNet和OccNet在语义场景完成任务中的性能,证明了OccNet在效率和有效性方面的优势。
- 未来工作和局限性:论文指出,尽管OccNet在多个下游任务上表现良好,但当前的注释仍然基于现有数据集,利用自监督学习进一步减少人工注释成本是一个有价值的研究方向。作者希望占用框架能成为自动驾驶的基础模型。