
知识点补充
非可微分后处理
非可微分后处理(non-differentiable post processing)指的是在数据或模型上应用的某些操作,这些操作无法进行微分计算。这意味着在这些操作之后,无法通过计算梯度来优化模型参数。在机器学习,特别是在训练神经网络的过程中,可微分性非常重要,因为它允许使用基于梯度的优化方法(如反向传播)来更新模型的参数。
非可微分后处理通常包括以下操作:
- 阈值化:将概率值转换为二元决策(例如,将输出分类为0或1)。
- 离散决策:涉及做出离散选择的任何操作,例如在一组值中选择最大值(如
argmax操作)。 - 舍入:通过舍入将连续值转换为整数。
- 非可微函数:涉及具有不连续点或梯度未定义的数学函数的操作,例如取数字的符号或应用某些不平滑的自定义函数。
由于这些操作是非可微的,它们会中断梯度的传播,使得无法直接在这些步骤上应用基于梯度的优化。因此,通常这些后处理步骤是在可微分部分的模型训练完成之后才应用的。
Deformable Attention
Deformable Attention 是一种用于计算机视觉中的注意力机制,旨在处理复杂场景下的视觉任务,尤其是在对象大小、形状、位置等特征存在较大变化的情况下。传统的注意力机制通常依赖于固定的、规则的感受野,而 Deformable Attention 则通过引入一种可变形的注意力机制,能够灵活地适应不同的对象形态和空间位置。
Deformable Attention 的核心思想是允许模型在不同空间位置上自适应地选择关注的特征点,而不是像传统注意力机制那样在整个图像或特征图上应用相同的注意力分布。这种机制通过学习偏移量,使得注意力能够在更大范围内选择重要的特征,从而更好地捕捉复杂场景中的关键信息。
Planning-oriented Autonomous Driving
UniAD,四个 Transformer。CVPR2023最佳论文,最重量级所以放在一开始。
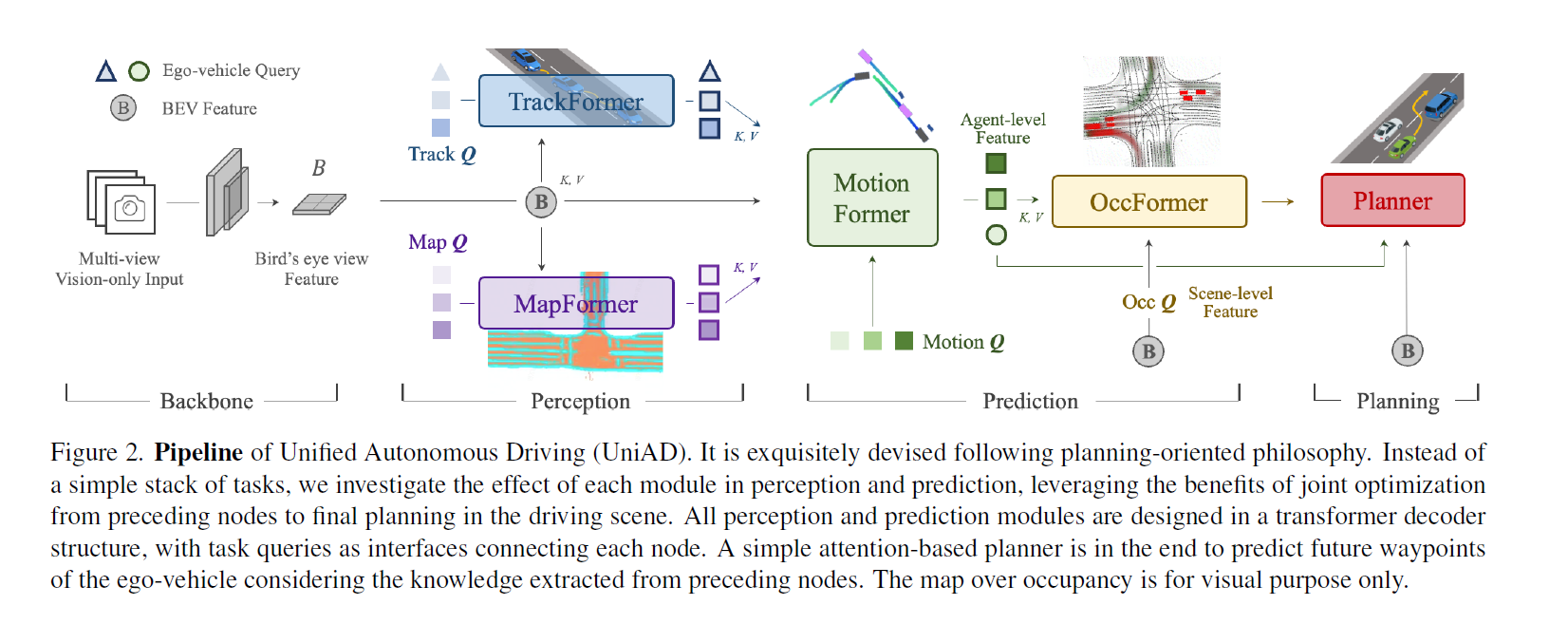
但是感觉还是比较模块化的,既然用了 BEVFormer(可以替换,但是也是 BEV encoder) 那其实也生成了高精地图和周围车辆信息这些东西了,后面的这些 Transformer 也是比较串行的一个接一个(除了 OccFormer 和 Planner)也接受了 Bev Feature Map 作为输入。
UniAD包含四个基于Transformer解码器的感知和预测模块,以及一个位于末端的规划模块。查询Q在连接管道中发挥作用,建模驾驶场景中实体的不同交互。具体来说,一系列多摄像头图像被输入特征提取器,得到的视角特征通过BEV编码器转换为统一的鸟瞰图(BEV)特征B。TrackFormer用于检测和跟踪代理;MapFormer表示道路元素并执行全景分割;MotionFormer捕捉代理和地图之间的交互并预测未来轨迹;OccFormer预测多步未来占用情况。最终,Planner利用来自MotionFormer的表达式强大的ego-vehicle查询进行规划预测,并避免碰撞。
-
TrackFormer: 具体来说,在每个时间步,初始化的检测查询负责检测首次感知到的新出现的目标,而跟踪查询则持续对前一帧中检测到的目标进行建模。
-
MapFormer:semantic map
这两个并行的transformer是什么结构?(得到中间表示再做embedding得到K, V?)
-
MotionFormer: MotionFormer predicts all agents’ multimodal future movements, i.e., top-k possible trajectories, in a scene-centric manner.
- OccFormer: Occupancy grid map is a discretized BEV representation where each cell holds a belief indicating whether it is occupied, and the occupancy prediction task is to discover how the grid map changes in the future. 但是这个 future occupancy map 是多 future 的?
- Planner: Planning without high-definition (HD) maps or predefined routes usually requires a high-level command to indicate the direction to go [11, 38]. Following this, we convert the raw navigation signals (i.e., turn left, turn right and keep forward) into three learnable embeddings, named command embeddings.
中文资料链接:https://zhuanlan.zhihu.com/p/632275644 https://blog.csdn.net/qq_34919792/article/details/131423998
CVPR 2024
Holistic Autonomous Driving Understanding by Bird’s-Eye-View Injected Multi-Modal Large Models
大模型 + 端到端
提出了一个名为NuInstruct的新数据集(To bridge these gaps, we introduce NuInstruct, a novel dataset with 91K multi-view video-QA pairs across 17 subtasks, where each task demands holistic information),以及一个端到端的方法BEV-InMLLM(Bird’s-Eye-View Injected Multi-Modal Large Language Model),用于提高自动驾驶任务中多模态大型语言模型(MLLMs)的性能。
LLM方面之前的工作:DriveGPT4 Talk2BEV
- 背景与动机:随着多模态大型语言模型(MLLMs)的兴起,基于语言的驾驶任务引起了研究者的兴趣。然而,现有研究通常只关注有限的任务,并且经常忽略了对鲁棒自动驾驶至关重要的多视角和时间信息。
- NuInstruct数据集:为了弥补现有研究的不足,作者引入了NuInstruct数据集,这是一个包含91K多视角视频-问答(video-QA)对的数据集,覆盖了17个子任务。categorized as follows: 1. Perception: The initial stage of recognizing surrounding entities. 2. Prediction: Forecasting the future actions of these entities. 3. Risk: Identifying imminent dangers, such as vehicles executing overtaking manoeuvres. 4. Planning with Reasoning: Developing a safe travel plan grounded in logical analysis. 每个任务都需要全面的信息,如时间、多视角和空间信息,显著提高了挑战级别。
- 数据生成方法:NuInstruct数据集是通过一种新颖的基于SQL的方法自动生成指令-响应对。这种方法受到人类驾驶逻辑进展的启发。
- BEV-InMLLM方法:为了应对NuInstruct提出的挑战性任务,作者提出了BEV-InMLLM方法,该方法将多视角、空间感知和时间语义整合到MLLMs中,以增强其在NuInstruct任务上的能力。BEV-InMLLM使用BEV注入模块来有效地获取与语言特征对齐的BEV特征。
- 实验结果:在NuInstruct数据集上的实验表明,BEV-InMLLM显著优于现有的MLLMs,在各种任务上提高了9%的性能。此外,消融研究显示MV-MLLM增强了多视角任务,而BEV-InMLLM对大多数任务至关重要,强调了空间信息的重要性。
模型结构
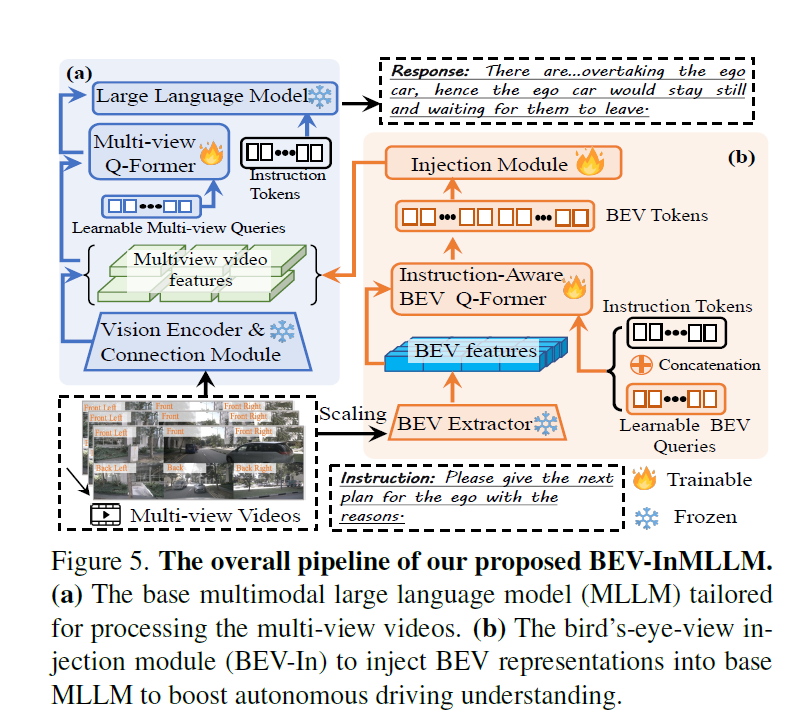
就是上了个LLM,然后把BEV特征也提取一下做利用,是一个缝合的工作。
具体的 injection:

DUALAD: Disentangling the Dynamic and Static World for End-to-End Driving
要点:动静分离
它通过将动态代理(如车辆和行人)和静态场景元素(如道路和车道标记)分开表示来实现端到端的驾驶任务。
DUALAD采用基于transformer-decoder的感知架构,使用两个流来明确地对动态对象进行对象中心表示和对静态场景元素进行基于网格的表示。该方法允许通过网络进行自我注意和交叉注意,同时引入了新的动态-静态交叉注意块,允许对象查询关注BEV查询,促进流之间的一致性。
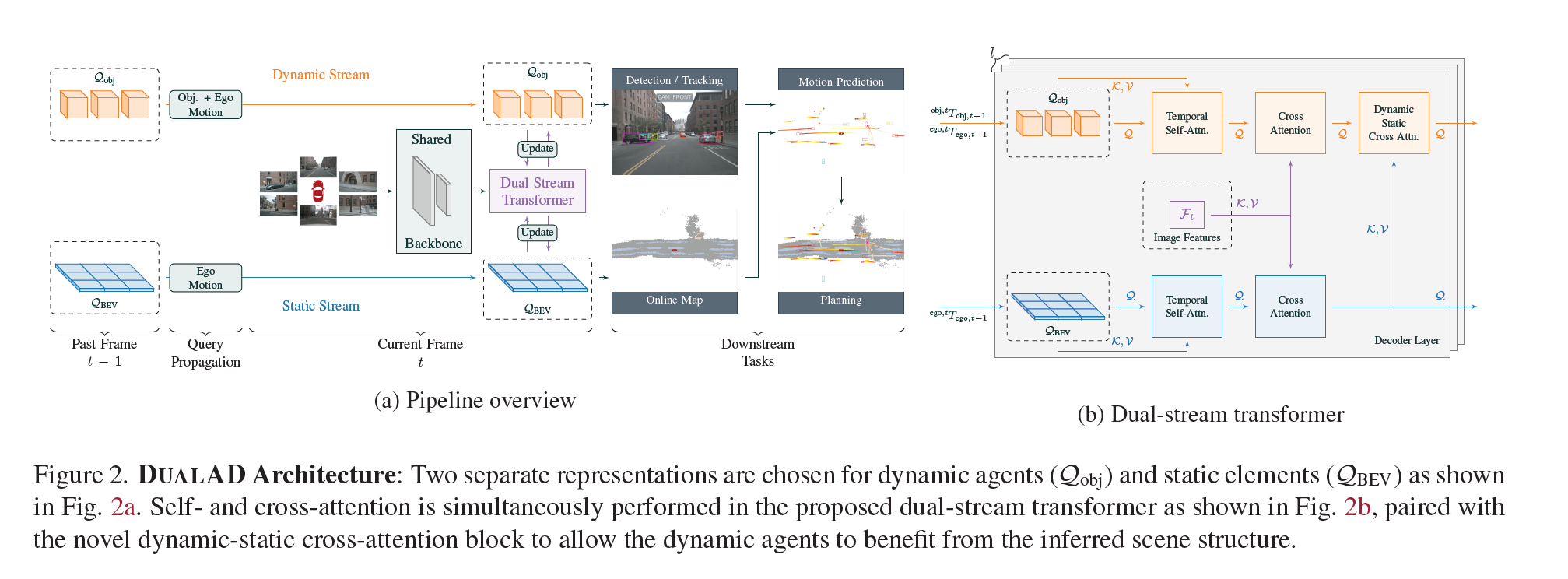
其实还是针对传统感知模块的 improvement,只是说整合进端到端的模块里的话,会优化模型表现而已。擦了个边吧。
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
- 知识蒸馏:为了解决这个问题,作者提出使用知识蒸馏技术,通过让一个较小的学生模型从较大的教师模型中学习,从而压缩模型。
- PlanKD框架:论文提出了PlanKD,这是首个针对压缩端到端运动规划器的定制知识蒸馏框架。它包含两个主要模块:
- 规划相关特征蒸馏:基于信息瓶颈原理,只蒸馏与规划相关的特征,而不是无差别地转移所有信息。
- 安全感知的航点注意力蒸馏模块:根据不同航点在运动规划中的重要性,动态分配航点的权重,鼓励学生模型准确模仿更重要的航点,从而提高整体安全性。
- 注意到评价标准是 CARLA Leaderboard,闭环
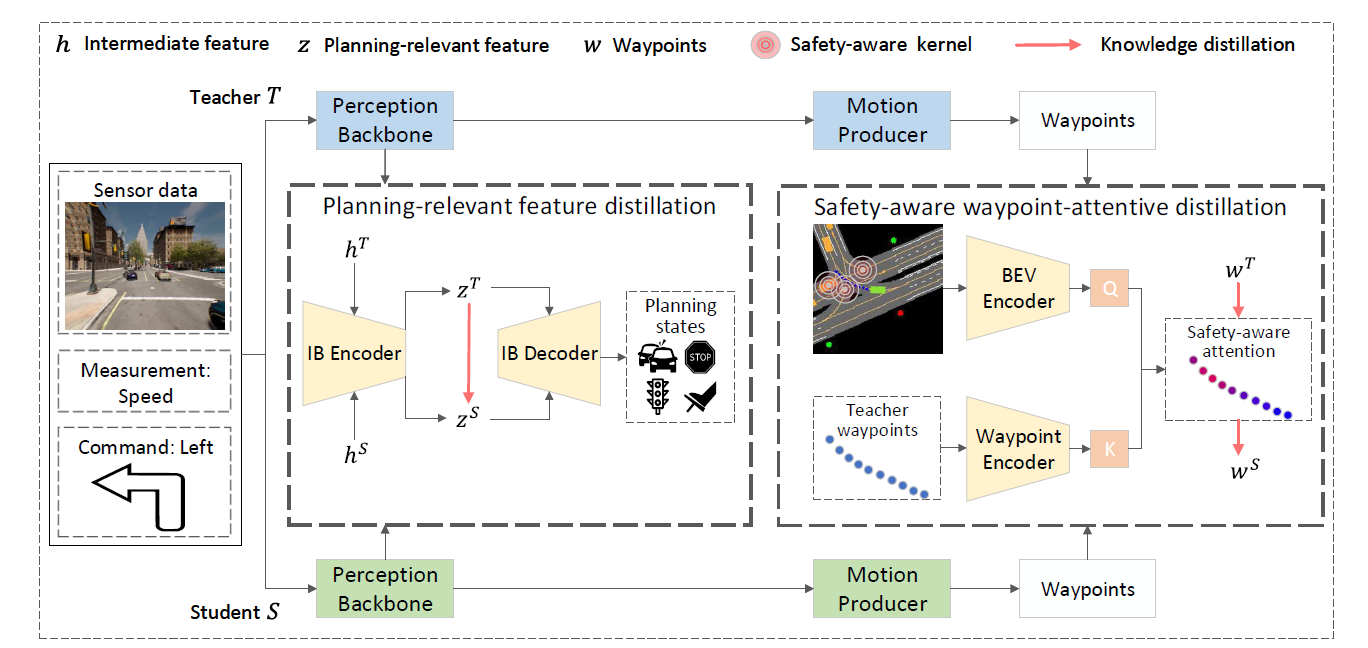
Teacher模型看起来用的是 InterFuser (transfuser和它是什么关系?)
可以看看它的 related works
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
本家论文,亲切
-
问题背景:端到端自动驾驶研究旨在从全栈角度实现自动驾驶功能,包括感知和规划。当前许多研究工作在nuScenes数据集上进行开放式循环评估,研究规划行为。
-
研究发现:作者观察到,由于nuScenes数据集的驾驶场景相对简单,导致现有的端到端模型在规划未来路径时,往往主要依赖于自我车辆的状态信息,如速度和加速度,而感知信息的利用不足。
-
数据集和评估指标的局限性:论文指出,现有的评估指标不能全面评估规划质量,可能导致从现有基准测试中得出的结论存在偏差。
-
新评估指标:为了解决这个问题,作者引入了一个新的评估指标,用于评估预测轨迹是否遵守道路规则。
-
基线模型:作者提出了一个简单的基线模型(BEV-Planner),该模型在不依赖感知注释的情况下,能够达到与现有方法相媲美的结果。
-
实验和讨论:通过一系列实验,作者讨论了自我车辆状态信息在现有端到端自动驾驶模型中的关键作用,并指出仅依赖自我状态信息可能导致安全风险。
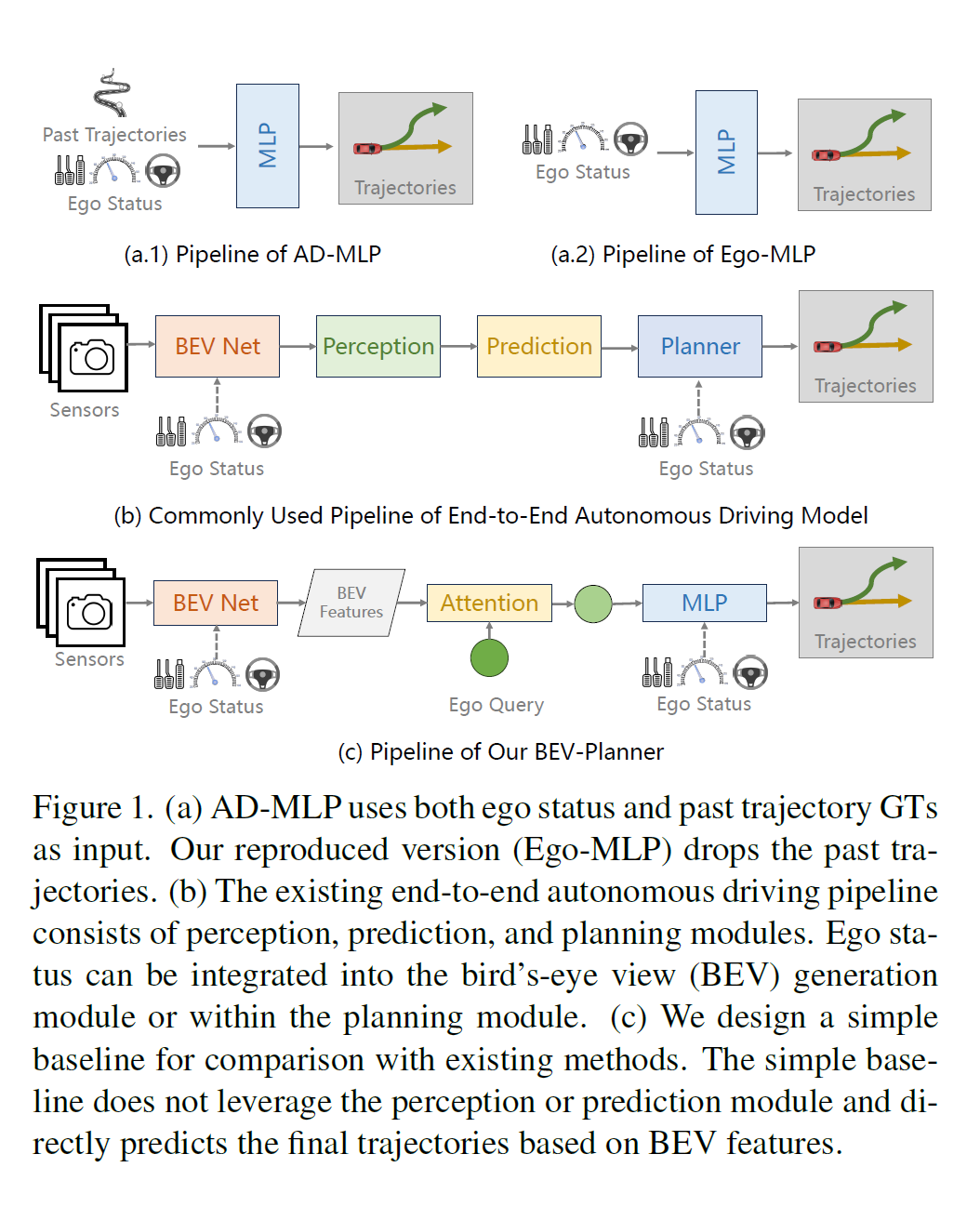
发现把perception砍了只用bev里的信息,和用perception模块产生的效果大差不差
- 输入:模型接受原始传感器数据作为输入,这些数据可能包括相机图像、激光雷达(LiDAR)数据等。
- BEV特征生成:首先,模型使用传感器数据生成鸟瞰图(Bird’s-Eye-View, BEV)特征。这些特征提供了车辆周围环境的全局视图。
- 历史BEV特征融合:模型将当前的BEV特征与历史BEV特征进行融合,以便捕捉时间维度上的信息。在论文中,作者提到他们没有执行特征对齐,而是直接将过去几个时间步的BEV特征沿通道维度进行拼接。
- Ego Query:模型使用可学习的嵌入向量作为自我查询(ego query),用于与BEV特征进行交互。
- 交叉注意力机制:模型采用交叉注意力机制(cross-attention)来加强自我查询与BEV特征之间的关联,从而提炼出与自我车辆状态相关的环境信息。
- MLP预测:经过交叉注意力机制处理后,模型使用多层感知器(MLP)来预测最终的轨迹。
- 输出:模型的输出是预测的轨迹,这些轨迹可以直接用于自动驾驶车辆的路径规划。
- 损失函数:为了训练模型,作者使用了L1损失函数来对轨迹进行监督学习。
- 不依赖感知注释:与现有方法不同,BEV-Planner不依赖于人类标注的数据,如边界框、跟踪ID、高精地图等。
- 评估:模型通过L2距离、碰撞率和新提出的路缘碰撞率(Curb Collision Rate, CCR)等指标进行评估。
Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
这篇是新的评价方法,没有涉及到模型
- 问题背景:自动驾驶中理解周围环境的变化对于安全和可靠的执行下游任务至关重要。现有的基于相机的占用估计技术大多限于表示当前的3D空间,没有考虑随时间轴变化的周围对象的未来状态。
- Cam4DOcc基准测试:为了将相机仅占用估计扩展到时空预测,作者提出了Cam4DOcc,这是一个新的基准测试,用于评估近期内周围场景变化的相机仅4D占用预测。
- 数据集构建:基于多个公开可用的数据集(包括nuScenes、nuScenes-Occupancy和Lyft-Level5),构建了一个新的数据集格式,提供了一般可移动和静态对象的顺序占用状态以及它们的3D反向向心流。
- 尽管OCFNet取得了显著的成果,但仅使用相机的4D占用预测仍然是一个挑战,尤其是在预测更长时间段内许多移动对象时。Cam4DOcc基准测试和全面的分析旨在提高对当前占用感知模型优缺点的理解,并作为未来4D占用预测研究的基础代码库。
VLP: Vision Language Planning for Autonomous Driving
又是大语言模型
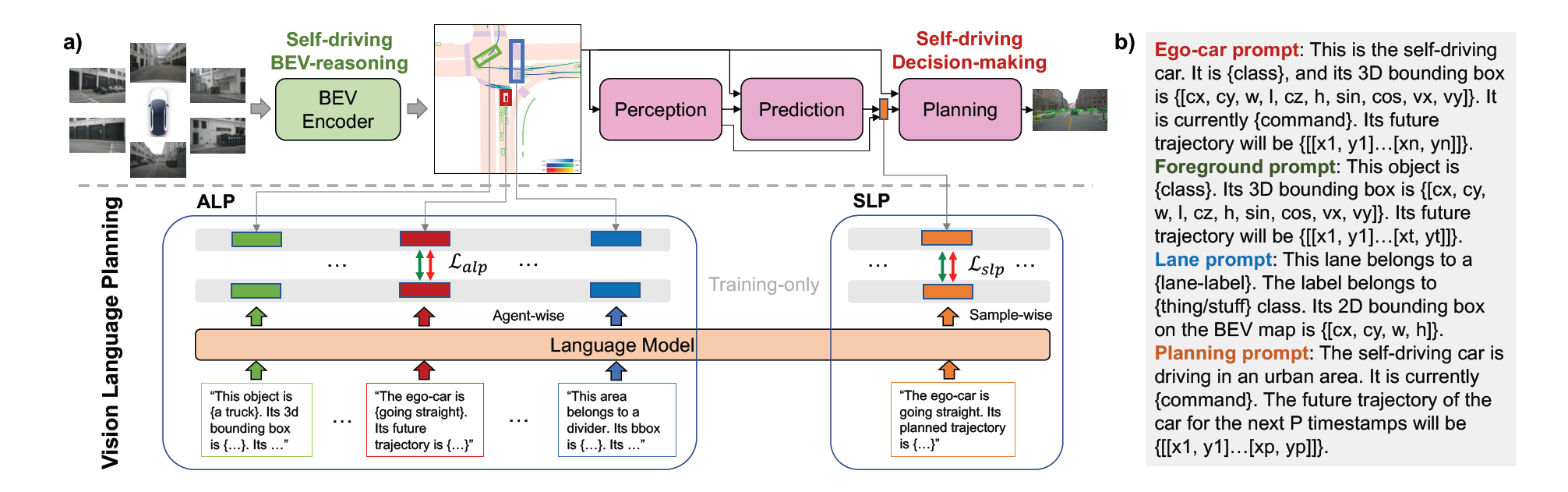
a) 提出的视觉语言规划 (VLP) 框架概述。 VLP分别通过ALP和SLP两个创新模块,从自动驾驶BEV推理和自动驾驶决策两个方面增强ADS。利用 LLM 和对比学习,ALP 进行智能体学习,以完善 BEV 的局部细节,而 SLP 则进行样本学习,以提高 ADS 的全局上下文理解能力。 VLP 仅在训练期间激活,确保在推理期间不会引入额外的参数或计算。 b) VLP 中使用的 Prompt 格式。
上文翻译参考 最新SOTA!VLP:自动驾驶视觉语言规划 - 知乎 (zhihu.com)
主要是把在不同情境下的 common sense 送入大语言模型(在推理的过程中训练LLM?),解决一些泛化方面的问题。
据本文所知,这是第一个将 LLMs 引入ADS的多个阶段以解决新城市和长尾案例的泛化能力的工作。
However, incorporation of the reasoning ability of LMs into real-world autonomous driving tasks, to address generalization and long-tail scenarios, is yet to be fully-explored. To bridge this gap, we propose a Vision Language Planning (VLP) framework, which integrates the commonsense capability of LMs into vision-based ADS for safe self-driving. Our VLP consists of two key components: Agent-centric Learning Paradigm (ALP) and Self-drivingcar-centric Learning Paradigm (SLP), leveraging LMs to enhance the ADS from reasoning and decision-making aspects, respectively.
In our proposed ALP, three kinds of BEV agents are considered: ego-vehicle (self-drivingcar), foreground (FG) objects, and lane elements.
The Agentcentric Learning Paradigm (ALP) concentrates on refining local details to enhance source memory reasoning, while the Self-driving-car-centric Learning Paradigm (SLP) focuses on guiding the planning process for the self-drivingcar (SDC).
更像个外挂在现有自动驾驶方法各个阶段的LLM,弥补自动驾驶学习过程中一些需要rule-base方法补强的部分,这里借用了LLM“更像人类”的推理方法,没有直接上rule这么生硬。
这篇文章的验证方法和UniAD VAD一样采用开环。
LMDrive: Closed-Loop End-to-End Driving with Large Language Models
LLM又一篇。我不禁开始思考,现在的LLM不都是一堆transformer吗?借用一个自然语言的中间态就能什么东西都往里面揉?(思)
论文原文:On the one hand, large language models (LLM) have shown impressive reasoning capabilities that approach “Artificial General Intelligence”,已经把LLM吹上天了。
…In this work, we seek to answer the question for the first time: Can we build cognitive autonomous driving systems on top of LLMs, that can interact with human passengers or navigation software simply by natural language?”
这个工作应该是做得最彻底的,直接就是一个多模态的LLM(经典用的LLaMA),暴力
-
LMDrive框架:首次提出一个语言引导的闭环端到端自动驾驶框架,能够通过自然语言指令与人类和导航软件进行交互。
-
数据集和基准测试:为了促进基于语言的闭环自动驾驶研究,作者公开了一个包含约64K指令跟随数据片段的数据集,以及一个测试系统处理复杂指令和驾驶场景能力的LangAuto基准测试。
-
实验:通过广泛的闭环实验验证了LMDrive的有效性。实验结果表明,LMDrive是第一个利用LLMs进行闭环端到端自动驾驶的工作。
-
方法:
- LMDrive使用多模态传感器数据(如摄像头和激光雷达)和自然语言指令作为输入,实时输出控制信号以在复杂场景中驾驶。
- 采用了预训练的LLM模型,并集成了多个摄像头-激光雷达数据编码器和可学习的输入/输出适配器。
- 引入了一种针对驾驶任务特别设计的预训练策略。
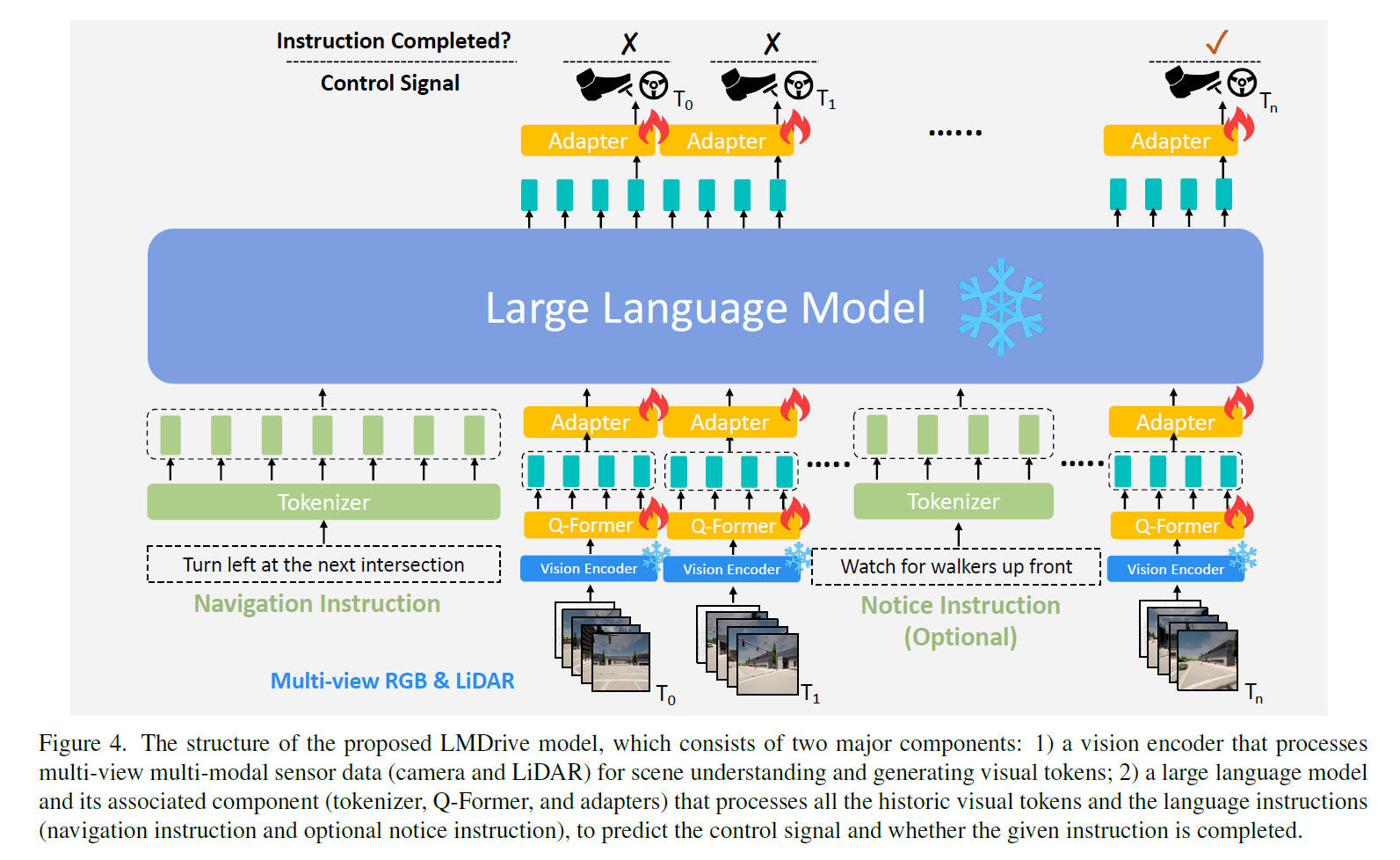
-
视觉编码器(Vision Encoder):
- 负责处理多视图多模态传感器数据,包括摄像头和激光雷达(LiDAR)数据。
- 包括一个2D骨干网络(例如ResNet)用于提取图像特征图,和一个3D骨干网络(例如PointPillars)用于处理点云数据。
- 使用BEV(鸟瞰图)解码器将图像和点云特征融合生成视觉标记(visual tokens)。
-
预训练预测头(Prediction Headers):
- 在视觉编码器的预训练阶段,附加预测头以执行对象检测、未来路径点预测和交通灯状态分类任务。
- 预测头仅在视觉编码器的预训练中使用,在后续的语言模型训练和推理中将被丢弃。
-
大语言模型(LLM)
LLM 在整个驾驶过程中作为“控制中心”和“大脑”存在。具体来说,语言模型需要处理视觉编码器为每一帧数据生成的视觉 tokens,理解自然语言指令,生成控制信号并预测指令是否完成。以下是其相关组件:
- Tokenizer:使用 LLaMA Tokenizer 将导航指令和可选的提示指令转换为文本 tokens。
- Q-Former:使用可学习 queries 对视觉 tokens 进行跨注意力层的降维,将每帧的视觉 tokens 数量减少到4。
- Adapter:使用2层 MLP 将 Q-Former 提取的视觉 tokens 转换为与语言 tokens 相同的维度,以作为 LLM 的输入。
LLM 接收一系列指令和视觉 tokens,并预测未来 2s 内的 waypoints。还同时使用一个2层 MLP 网络用于预测给定指令是否完成。为增强监督信号,模型训练过程中会对每个历史帧进行预测并计算相应的损失函数。在模型推断时仅执行最新帧的预测。最终的控制信号由两个 PID 控制器生成,用于横向和纵向控制,以使车辆跟踪模型预测的 waypoints 的位置和速度。
-
相关组件:
- 分词器(Tokenizer):将导航指令和可选的通知指令转换为文本标记。
- Q-Former:用于减少每帧视觉标记的数量,通过交叉注意力层将视觉标记的数量减少到M个。
- 适配器(Adapters):用于将视觉标记转换为与语言标记相同维度的标记,以便输入到LLM中。
-
动作预测(Action Prediction):
- LLM接收一系列指令和视觉标记,预测动作标记。
- 使用两个PID控制器分别进行纵向和横向控制,以跟踪预测的路径点的航向和速度。
-
训练目标(Training Objectives):
- 在微调LLM及其相关组件时,考虑两种损失项:L1路径点损失和指示指令完成情况的分类损失。
-
训练细节(Training Details):
- LMDrive的训练包括两个阶段:视觉编码器的预训练阶段和指令微调阶段。
- 在预训练阶段,视觉编码器独立训练,以理解场景。
- 在指令微调阶段,整个系统在指令的指导下进行端到端自动驾驶训练。
-
LangAuto基准测试(LangAuto Benchmark):
-
另外,LMDrive 还提出了LangAuto(Language-guided Autonomous Driving)CARLA 测试框架,这是第一个评估在语言指令下闭环驾驶性能的测试框架。与先前的基于 CARLA 模拟器的测试框架(例如 Town05 和 Longest6)相比,之前的框架使用离散的驾驶指令或目标路径点引导自动驾驶智能体,而LangAuto 仅为自动驾驶车辆提供自然语言中的导航指令和可选的提示指令。
LangAuto 涵盖 CARLA 的 8 个城镇,包括各种场景,共 16 种环境条件,涵盖不同天气和光线条件。LangAuto 有三个 tracks 测试自动驾驶算法的指令遵循能力:
- LangAuto track:根据智能体当前的位置提供导航指令,分为三个子赛道,以测试不同路线长度下模型的性能。
- LangAuto-Notice track:在 LangAuto 基础上添加提示指令,模拟实时提示场景。
- LangAuto-Sequential track:合并连续的2到3个指令,以模拟多句指令的情况。
此外,LangAuto 中还以约 5% 的概率随机提供误导性指令,要求智能体拒绝并执行安全操作,直到下一个正确指令。这样设计旨在全面评估智能体在语言引导下的驾驶性能。
-
Q-Former好像总是出现,要看一下的。
中文解析:LMDrive: 大语言模型加持的闭环端到端自动驾驶框架-CSDN博客
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
中文解析:https://blog.csdn.net/lijj0304/article/details/136440362
最意想不到的一篇(产生疑问最多的一篇),有点多重宇宙多结局那意思,直接生成不同决策产生的该世界的“未来”。不过这样的话开销真的不大吗?
不过仔细想了一下,只是做个视频推理,把perception、prediction那些都省了,只要算出未来的视频信息,再从这些未来的图像信息进行判断,就足以做出决策。
但是这种基于未来推断和车辆的未来实际行为真的会一致吗,总感觉不太靠谱。。。如果经过了preception和prediction,最起码会有准确的对于场景中各物体的感知,不会把这一步留给“未来”,有点剑走偏锋了。而且究竟生成多少种未来最好?这些怎么确定?
会想到nuScenes数据集“几乎都是直行”的缺陷,确实未来的选项不多,怕不是变道占了大多数(事实上论文的演示也是这样)。这样的话这个工作还有泛用性吗?
“结合多视角的图像,时间序列,空间布局,文本等各种信息构造世界模型。预测不同动作自动生成场景做评估,挑选最好的规划”
- 问题背景:在自动驾驶中,提前预测未来事件并评估可预见的风险对于提高道路安全性和效率至关重要。然而,现有的端到端规划器在面对分布外(OOD)情况时可能缺乏足够的泛化能力。
- Drive-WM模型:为了解决这个问题,作者提出了Drive-WM,这是一个能够基于当前状态和自我行为预测未来状态的世界模型。通过提前可视化未来并从不同的未来中获得反馈,Drive-WM能够提供更合理的规划,增强端到端自动驾驶的泛化能力和安全性。
- 多视图视频生成:Drive-WM通过联合时空建模,生成高保真的多视图视频,这对于自动驾驶场景中的全面环境观察至关重要。
- 模型结构:Drive-WM引入了多视图和时间建模,通过潜在视频扩散模型来共同生成多个视图和帧。为了增强多视图一致性,作者提出了一种分布分解方法来预测中间视图,以提高视图间的一致性。
- 条件接口:Drive-WM引入了一个统一的条件接口,能够灵活地使用多种异构条件,如图像、文本、3D布局和动作,大大简化了条件生成。
- 端到端规划应用:作者探索了将世界模型应用于端到端规划的潜力,通过实验展示了该方法在规划的整体合理性和在分布外情况下的鲁棒性。
- 实验:在nuScenes数据集上进行的实验验证了Drive-WM在生成高质量、一致性和可控性多视图视频方面的领先性能,并展示了其在规划中的有效性。(经典开环,L2 + Collision)
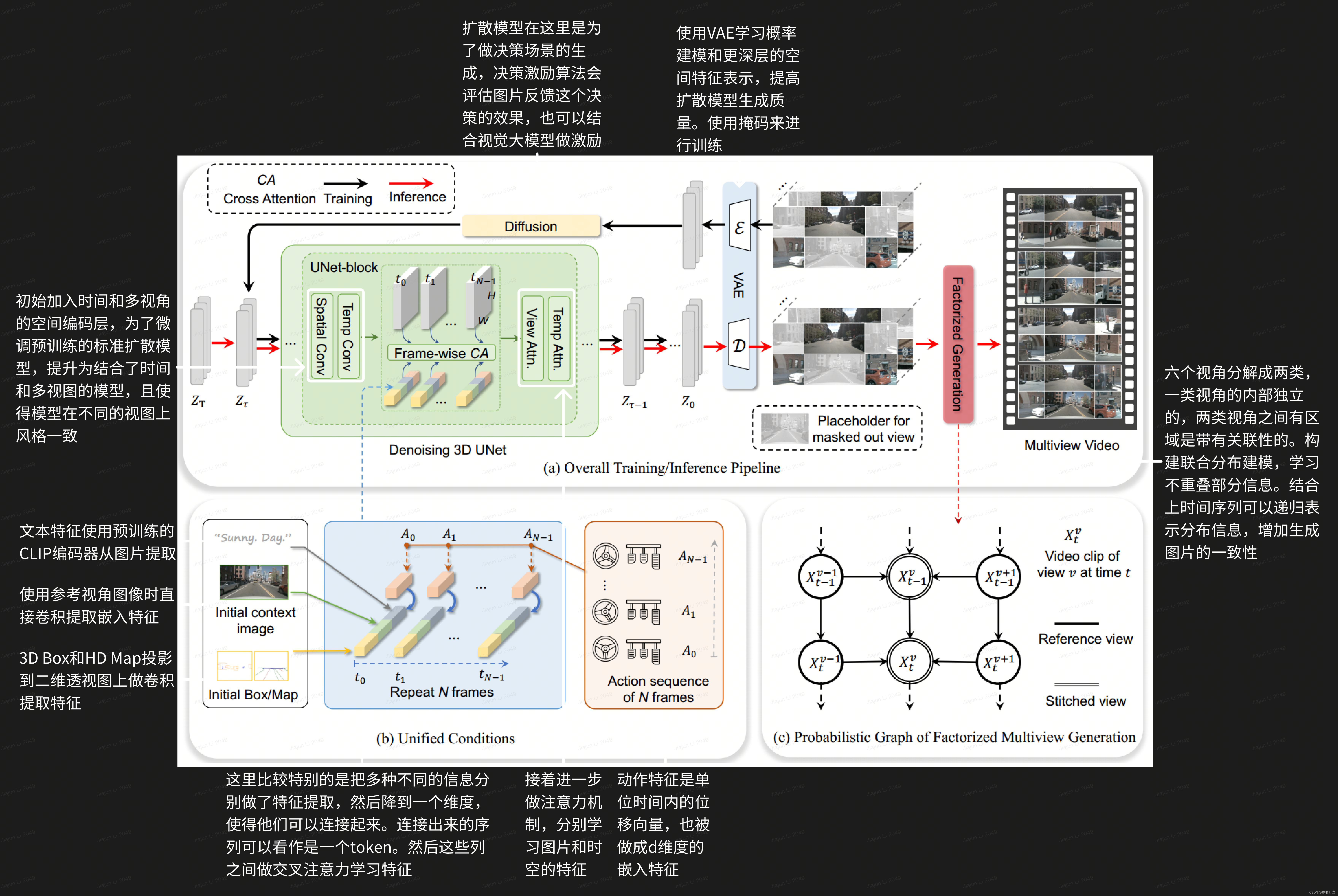
使用预训练好的模型,输入真实的视角,然后构建决策树的形式,模型生成各个轨迹规划的视频并且结合激励函数的反馈做最佳的选择。
决策的激励:1.地图激励(车道上合适的位置,远离路边缘,中心线一致)2.物体激励(安全的行车距离)
进一步从非矢量化表示中获得激励,如GPT-4V去获取图片进一步的特征信息,增加驾驶安全性。
PARA-Drive: Parallelized Architecture for Real-time Autonomous Driving
在不砍模块的前提下把并行化做到极致的工作。这篇论文给了一个很有利于综述的进化图
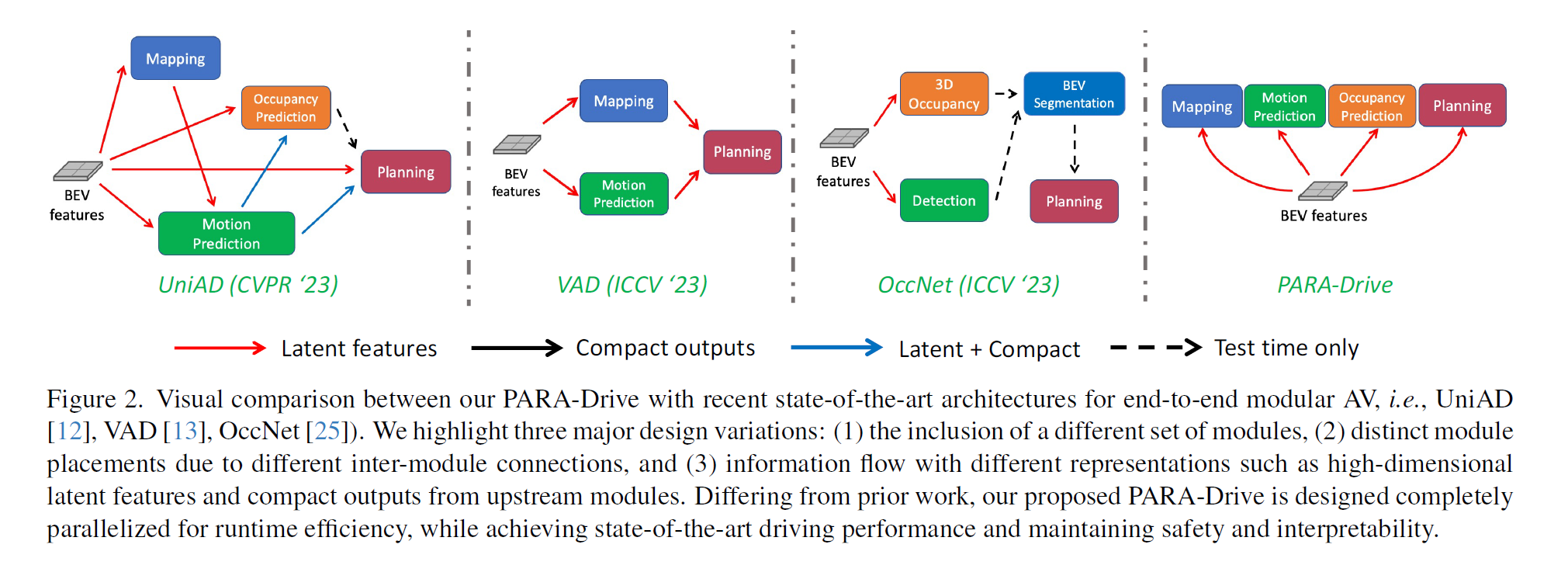
其实这是李工作的进化版,李只分析了Perception和后续模块的相关性,英伟达全做了。而且从文章来看所有排列组合都做了。唉,还得是人家人力物力充足呀。
以下部分参考 端到端自动驾驶新突破:Nvidia提出全并行PARA-Drive,入选CVPR24!-CSDN博客
最近很多研究提出了由可区分模块组成的端到端自动驾驶汽车(AV)架构,实现了最先进的驾驶性能。与传统的感知-预测-规划架构相比,端到端架构更具有优势(例如,消除了组件之间的信息瓶颈,减轻了模块集成的挑战),但是端到端架构仍然使用传统架构的模块和任务组合。然而,迄今为止还没有研究系统地分析过这些模块的必要性或它们的连接关系、排列顺序和内部表示对整体驾驶系统性能的影响。
针对上述空白,本研究对端到端自动驾驶汽车架构的设计空间进行了全面探索。作者的研究成果最形成了PARA-Drive1 :一种完全并行的端到端自动驾驶架构。PARA-Drive 不仅在感知、预测和规划方面达到了最先进的性能,而且在不影响可解释性或安全性的前提下,将运行速度显著提高了近3倍。
但是评价方式还是开环nuScenes,英伟达也注意到了nuScenes数据集绝大多数都是直行的问题。论文最后也提出移植到闭环。
ICCV 2023
Hidden Biases of End-to-End Driving Models
transfuser的改进,暂时没有细看。因为是transfuser,自然而然地用的是CARLA闭环。
DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving
利用教师-学生范式和强化学习搞出来的。
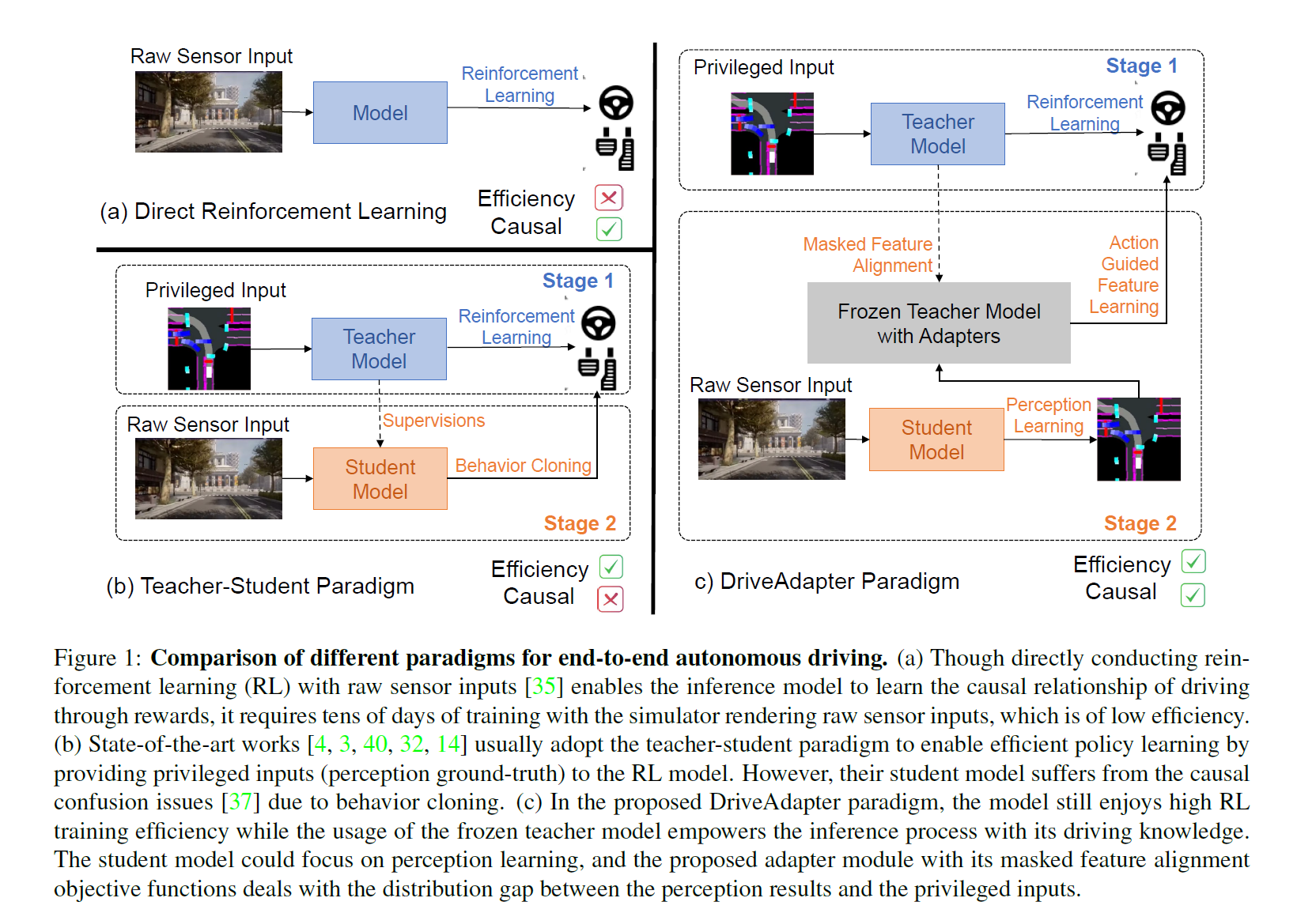
- 问题背景:端到端自动驾驶系统旨在构建一个完全可微分的系统,直接将原始传感器数据输入并输出规划好的轨迹或控制信号。现有的方法通常采用“教师-学生”范式,其中教师模型使用特权信息(周围代理和地图元素的真实状态)学习驾驶策略,而学生模型只能访问原始传感器数据,并通过行为克隆学习教师模型收集的数据。
- 现有问题:在当前的教师-学生范式下,学生模型仍然需要从头开始学习规划头,这可能因为原始传感器输入的冗余和噪声性质以及行为克隆的因果混淆问题而变得具有挑战性。
- DriveAdapter方法:论文提出了DriveAdapter,这是一种采用适配器的模型,通过在学生(感知)和教师(规划)模块之间进行特征对齐目标函数来处理分布差异。此外,由于纯基于学习的教师模型本身并不完美,有时会违反安全规则,论文提出了一种行动引导的特征学习方法,通过掩码将手工制定的规则的先验知识注入学习过程中。
- 实验结果:DriveAdapter在CARLA模拟器的多个闭环模拟基准测试中取得了最先进的性能。
- 贡献总结:
- 首次彻底探索了直接利用通过强化学习训练的教师模型进行端到端自动驾驶任务的范式。
- 提出了DriveAdapter以及掩码特征蒸馏策略,结合这两种技术,在两个公共基准测试中实现了最先进的性能。
- 提供了详尽的消融研究和其他相关尝试,为这种新的解耦范式提供了更多的见解和理解。
- 结论与未来工作:DriveAdapter通过利用通过强化学习训练的教师模型中的驾驶知识,实现了端到端自动驾驶流程中的直接应用。为了克服不完美的感知和教师模型问题,提出了掩码特征对齐和行动引导目标函数的适配器。论文希望这能为端到端自动驾驶的研究开辟新的方向,并指出提高基于学习的教师模型的性能将有助于DriveAdapter的性能。
- 限制与致谢:论文指出教师模型的性能是DriveAdapter性能的上限,因此提高教师模型的性能将有助于DriveAdapter。
Scene as Occupancy
OccNet,使用体素代替传统空间表示(BEV + Bounding Box),重要工作
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
目前的SOTA,重要工作
CVPR 2023
Planning-oriented Autonomous Driving
开篇就是,不再赘述。
Think Twice before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving
有中文分析:Think_Twice_before_Driving(论文总结)_think twice before driving: towards scalable decod-CSDN博客
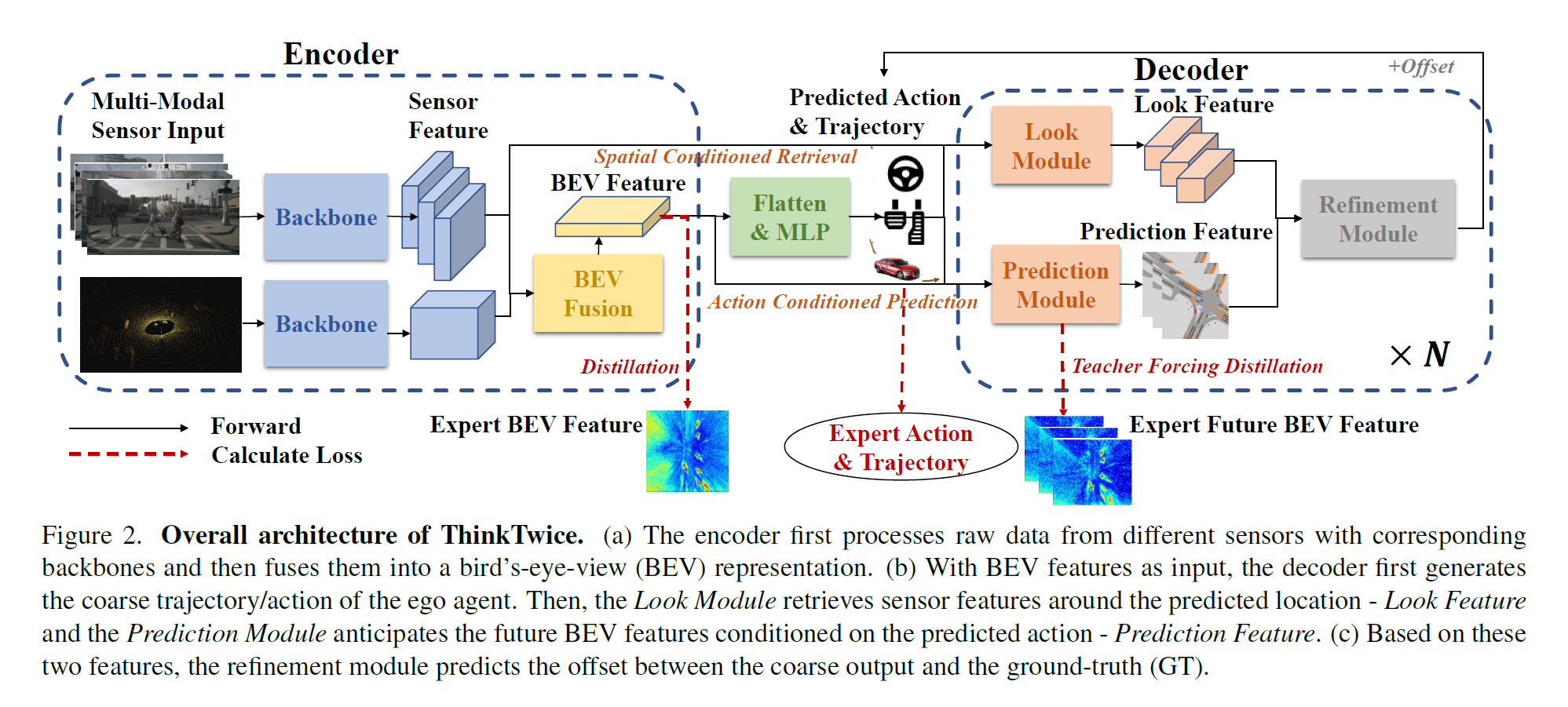
- Encoder: “raw sensor data” -> “representation vector”
- Decoder: “representation vector” -> “future trajectories/actions”
论文的核心贡献是提出了一个名为ThinkTwice的端到端自动驾驶框架,旨在通过扩展解码器的容量来提高自动驾驶的性能。以下是对论文内容的具体概括:
- 问题背景:端到端自动驾驶系统直接将原始传感器数据映射到控制信号或未来轨迹,近年来取得了显著进展。现有方法通常采用编码器-解码器范式,其中编码器从原始传感器数据中提取特征,解码器输出车辆的未来轨迹或动作。这种范式存在的问题是编码器无法访问车辆的预期行为,将寻找安全关键区域和推断未来情况的负担留给了解码器。
- 主要贡献:
- 提出了一种可扩展的解码器范式,通过在粗略预测的基础上进行细化,强调了扩大解码器容量的重要性。
- 设计了一个解码器模块,通过回顾安全关键区域并基于预测的行动/轨迹预测未来场景,将空间-时间先验知识和密集监督注入训练过程。Decoder模块包括三个子模块:Look Module、Prediction Module和Refinement Module。其中,Look Module模块用于将人类驾驶员的先验知识(目标位置)注入到模型中,提高模型的泛化能力;Prediction Module模块用于预测场景的未来发展,以及提供监督信号;Refinement Module模块用于通过对预测结果的微调来提高预测精度。这三个子模块分别对应于解码器中的三个阶段:粗略预测、注入先验知识、微调预测结果。通过将这三个子模块结合起来,能够获得更准确的自动驾驶预测结果。
- 在CARLA模拟器的两个竞争性闭环自动驾驶基准测试中展示了最先进的性能,并通过广泛的消融研究验证了所提出模块的有效性。
- 方法论:
- ThinkTwice框架由编码器和解码器组成,编码器将原始传感器数据转换为表示向量,解码器基于该向量生成自车的未来轨迹或动作。
- 采用粗到细的策略,首先通过MLP生成粗略的未来轨迹和动作,然后通过查找模块(Look Module)检索预测位置周围的特征,以及通过预测模块(Prediction Module)生成基于粗略动作的未来场景表示。
- 利用这两个模块的特征,通过预测粗略预测与地面真实值之间的偏移来进行细化。
- 实验结果:在CARLA模拟器的Town05 Long和Longest6基准测试中,ThinkTwice在闭环自动驾驶任务中取得了最先进的性能,超过了先前的最先进技术。
- 结论:论文强调了在端到端自动驾驶中,解码器(决策部分)与编码器(感知部分)同等重要,并希望本研究的探索能够激发社区进一步的研究努力。
ReasonNet: End-to-End Driving with Temporal and Global Reasoning
论文提出了一个名为ReasonNet的新型端到端自动驾驶框架,该框架充分利用了驾驶场景中的时间(Temporal)和全局(Global)信息。ReasonNet通过推理对象的时间行为,有效处理了不同帧之间的特征交互和关系。同时,通过全局信息的推理,提高了对整体场景感知性能,并有助于检测被遮挡对象等不利事件,尤其是预测从遮挡区域突然出现的潜在危险。
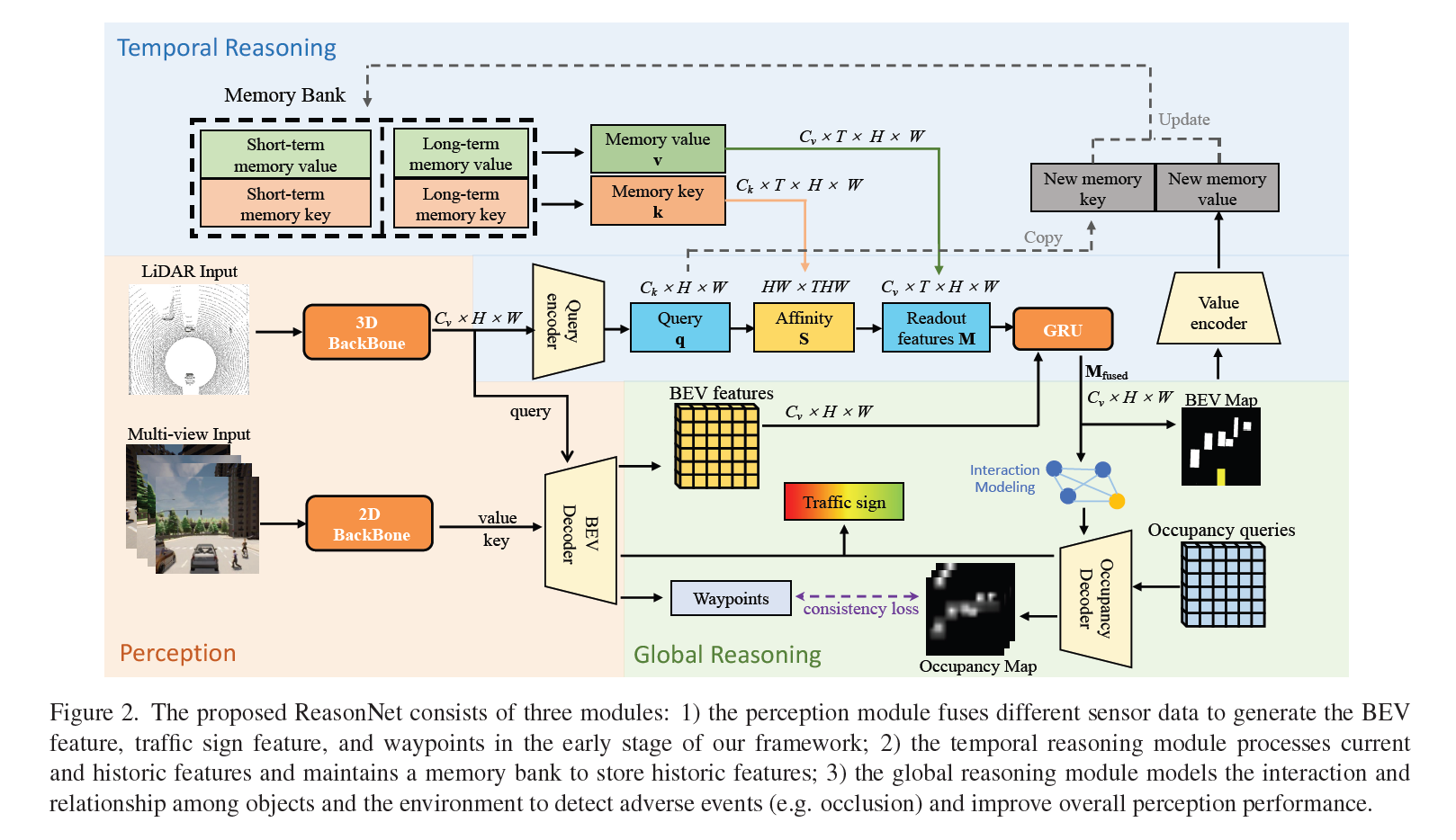
主要贡献包括:
- 提出了一个新颖的时序和全局推理网络(ReasonNet),增强了对历史场景推理的能力,以高保真度预测场景的未来演变,并在被遮挡情况下改善全局上下文感知性能。
- 引入了一个新的基准测试,称为DriveOcclusionSim(DOS),包含多种城市驾驶中的遮挡场景,用于系统性评估遮挡事件,并公开了这个基准。
- 在多个复杂的城市场景基准测试上验证了所提方法的有效性,模型在CARLA自动驾驶排行榜的传感器轨道上排名第一。
有点眼花缭乱了,脑子要炸啦。暂时歇歇,去看比较老的论文去。