
前情提要
这是一篇从 LLM4Drive: A Survey of Large Language Models for Autonomous Driving 伸展出去的笔记,主要看看自动驾驶用大语言模型。唉,大语言模型,LMDrive 那篇文章对 LLM 的赞誉之词还历历在目。
… large language models (LLM) have shown impressive reasoning capabilities that approach “Artificial General Intelligence”…
…大语言模型在目前已经拥有了接近“通用人工智能”的惊艳表现…
看到如此正面的描述总是要从反面思考一下。在我看来,除了 LLM 模型结构本身适宜多模态数据处理(用不同的embedding当自然语言一样处理就可以了)之外,在比较抽象的认识层面上,LLM 给各种信息提供了一个自然语言的中间表示,来汇总处理各种信息(或者这两点其实是一点?)。这是一种类似人类思维方式的处理,但是也带来一个问题,就是 LLM 能力的上限决定了基于 LLM 的自动驾驶模型的上限,人类自然语言体系表达能力的上限又决定了 LLM 能力的上限(尤其体现于那些基于 Q-A 的模型上,非常依赖自然语言表示)。LLM 固然是通用的,也确实是现在看来最通用的模型,给很多多模态问题提供了可以接受的解决方案,理论上可以达到按照自然语言进行思考的人类驾驶员的水平;但是要捅破这层上限,是否还需要其他的方式?
Anyway,在解决多模态问题,尤其是自动驾驶这样一个 multi-task 的问题方面,LLM 确实是当下最可靠的解决方案之一。话不再多说了,下面是笔记正文。
分类
因为自动驾驶要做的任务本身就比较多,所以LLM应用的场景也不一样。
比较自然产生的是 Perception 和 Planning & Control 。紧接着有包括世界模型(比如之前看过的这篇)等应用方式的生成式 Generation (Diffusion) LLM。然后是基于问答的 Question Answering (QA) 用 LLM,最后为了评估,还有 Evaluation & Benchmark。

Goole Scolar Citations (up to 2024/9/9)
Perception: Tracking
48 Language prompt for autonomous driving
Perception: Detection
39 Hilm-d: Towards high-resolution understanding in multimodal large language models for autonomous driving
Perception: Prediction
17 Can you text what is happening? integrating pre-trained language encoders into trajectory prediction models for autonomous driving
17 Mtd-gpt: A multi-task decision-making gpt model for autonomous driving at unsignalized intersections
5 LC-LLM: Explainable Lane-Change Intention and Trajectory Predictions with Large Language Models
0 LeGo-Drive: Language-enhanced Goal-oriented Closed-Loop End-to-End Autonomous Driving
2 Large Language Models Powered Context-aware Motion Prediction
Planning & Control: Prompt Engineering
13 Empowering Autonomous Driving with Large Language Models: A Safety Perspective
10 Personalized Autonomous Driving with Large Language Models: Field Experiments (name modified)
35 ChatGPT as your vehicle co-pilot: An initial attempt
40 Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles
86 Languagempc: Large language models as decision makers for autonomous driving
32 Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous Driving
34 Surrealdriver: Designing generative driver agent simulation framework in urban contexts based on large language model
67 Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles
77 Dilu: A knowledge-driven approach to autonomous driving with large language models
5 LLM-assisted light: Leveraging large language model capabilities for human-mimetic traffic signal control in complex urban environments
11 AccidentGPT: Accident analysis and prevention from V2X environmental perception with multi-modal large model
20 Llm-assist: Enhancing closed-loop planning with language-based reasoning
7 Driving Everywhere with Large Language Model Policy Adaptation
Planning & Control: Fine-tuning Pre-trained Model
40 Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving
48 Lmdrive: Closed-loop end-to-end driving with large language models
38 A language agent for autonomous driving
119 Gpt-driver: Learning to drive with gpt
69 Drivelm: Driving with graph visual question answering
114 Drivegpt4: Interpretable end-to-end autonomous driving via large language model
79 Driving with llms: Fusing object-level vector modality for explainable autonomous driving
17 Mtd-gpt: A multi-task decision-making gpt model for autonomous driving at unsignalized intersections
0 KoMA: Knowledge-driven Multi-agent Framework for Autonomous Driving with Large Language Models
1 Asynchronous Large Language Model Enhanced Planner for Autonomous Driving
34 Drivevlm: The convergence of autonomous driving and large vision-language models
16 Rag-driver: Generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model
9 VLP: Vision Language Planning for Autonomous Driving
11 Dme-driver: Integrating human decision logic and 3d scene perception in autonomous driving
Generation (Diffusion)
17 Adriver-i: A general world model for autonomous driving
16 DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
59 Drivedreamer: Towards real-world-driven world models for autonomous driving
30 Language-guided traffic simulation via scene-level diffusion
90 Gaia-1: A generative world model for autonomous driving
39 Magicdrive: Street view generation with diverse 3d geometry control
24 Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
0 ChatScene: Knowledge-Enabled Safety-Critical Scenario Generation for Autonomous Vehicles
1 REvolve: Reward Evolution with Large Language Models for Autonomous Driving
11 Genad: Generative end-to-end autonomous driving
7 Drivedreamer-2: Llm-enhanced world models for diverse driving video generation
12 Editable scene simulation for autonomous driving via collaborative llm-agents
5 LLM-assisted light: Leveraging large language model capabilities for human-mimetic traffic signal control in complex urban environments
3 LangProp: A code optimization framework using Large Language Models applied to driving
Question Answering (QA): Visual QA
40 Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving
69 Drivelm: Driving with graph visual question answering
12 Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving
12 Lingoqa: Video question answering for autonomous driving
26 Dolphins: Multimodal language model for driving
0 A Superalignment Framework in Autonomous Driving with Large Language Models
3 Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
9 Transgpt: Multi-modal generative pre-trained transformer for transportation
Traditional QA
8 Domain knowledge distillation from large language model: An empirical study in the autonomous driving domain
14 Human-centric autonomous systems with llms for user command reasoning
4 Engineering safety requirements for autonomous driving with large language models
3 Hybrid Reasoning Based on Large Language Models for Autonomous Car Driving
Evaluation & Benchmark
46 On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving
1 GPT-4V Takes the Wheel: Promises and Challenges for Pedestrian Behavior Prediction
15 Lampilot: An open benchmark dataset for autonomous driving with language model programs
6 Evaluation of large language models for decision making in autonomous driving
0 Testing Large Language Models on Driving Theory Knowledge and Skills for Connected Autonomous Vehicles
1 Probing Multimodal LLMs as World Models for Driving
9 Embodied understanding of driving scenarios
8 LimSim++: A Closed-Loop Platform for Deploying Multimodal LLMs in Autonomous Driving
7 OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
2 AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
Datasets
工欲善其事,必先利其器。所以在这里稍微调整一下原综述论文的顺序,先来看数据集。
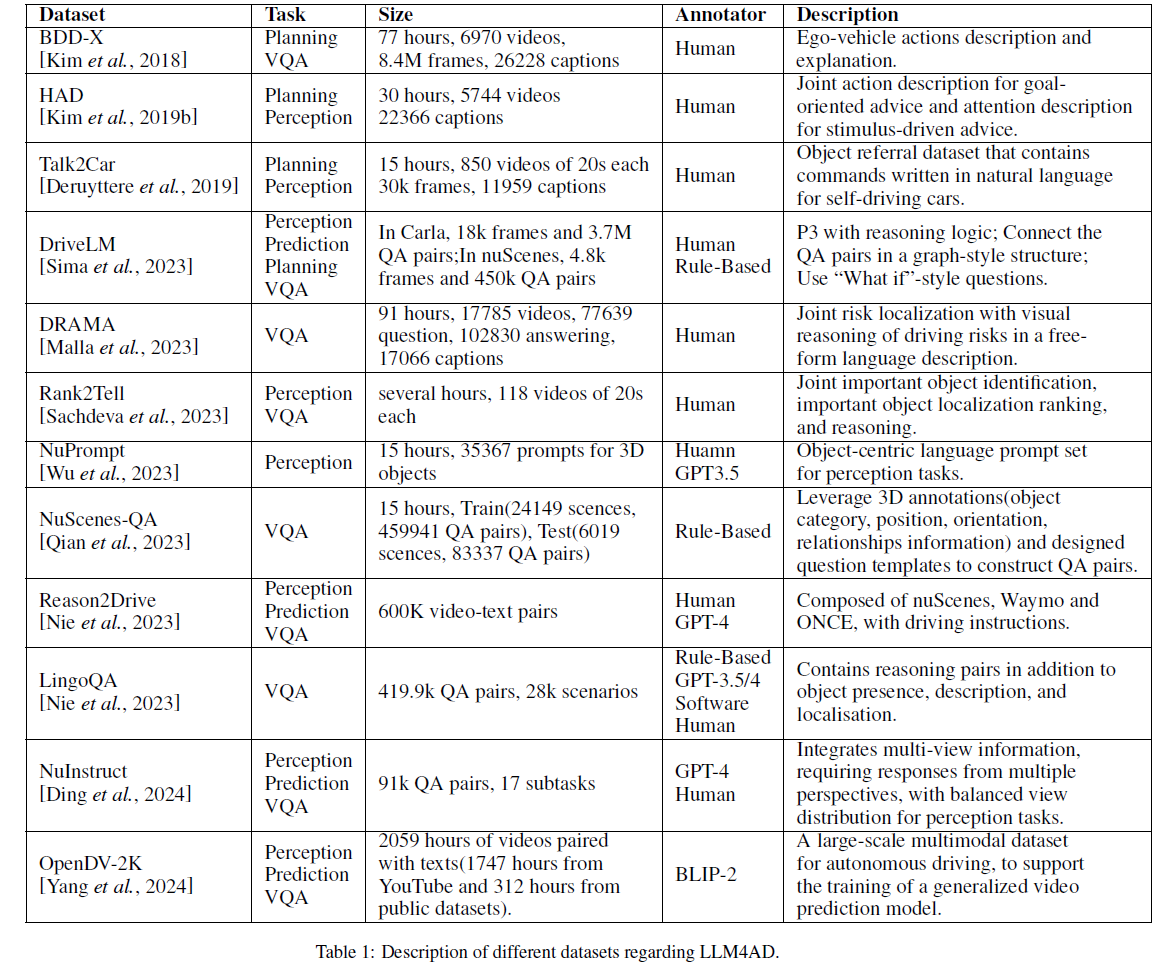
可以看到绝大多数还是人力标注的。
BDD-X (2018) (Planning + VQA)
Berkeley Deep Drive-X (eXplanation) Dataset
链接:https://github.com/JinkyuKimUCB/BDD-X-dataset
这是一个解释驾驶员行为的数据集。对于视频信息,标注的格式是一个description(驾驶员在做什么)和一个explanation(驾驶员为什么这样做)
We focus on generating textual descriptions and explanations, such as the pair: “Vehicle slows down” (description) and “Because it is approaching an intersection and the light is red” (explanation)
explanation的设置还是很有必要的,可以用于避免一些倒果为因的问题。(想起了 CILRS)
HAD (2019) (Planning + Perception)
Honda Research Institute-Advice
链接:https://usa.honda-ri.com/had
同样地,输入是运行信息,但是除了视频信息之外还提供了 CAN-BUS 控制信息。嘶,这个控制信息是所有型号的车辆都是统一的吗?还是说翻译成 Honda 的车的 Behaviour 再使用?有一些神奇。
标注的信息是“Advice”,(1)目标导向的建议(自上而下信号)——用于影响车辆在导航任务中的行为;(2)刺激驱动的建议(自下而上信号)——传达一些视觉刺激,这些刺激是用户期望车辆控制器主动关注的。
原文:
Advices consist of (1) goal-orientedadvice (top-down signal) - to influencethe vehicle in a avigation task and (2) stimulus-driven advice (bottom-upsignal) - conveys some visual stimulithat the user expects their attention tobe actively looked by the vehicle controller
Talk2Car (2019) (Planning + Perception)
链接:https://talk2car.github.io/
Talk2Car 是基于 nuScenes 的,按官网的说法是加上了更多模态的传感器输入(其实我记得现在 nuScenes 的模态已经不少了,在那时候只有图像和 bounding boxes 吗?)。最主要的是 “Talk”:标注信息中有对车辆下的指令,“we consider an autonomous driving setting, where a passenger can control the actions of an Autonomous Vehicle by giving commands in natural language.”
例子:
You can park up ahead behind the silver car, next to that lamp post with the orange sign on it
同时在图像输入中,silver car 被标注。
DriveLM (2023) (Perception + Prediction + Planning + VQA)
OpenDriveLab的工作。链接:https://github.com/OpenDriveLab/DriveLM
这个数据集是基于 Carla 和 nuScenes 的。
DriveLM-Data is the first language-driving dataset facilitating the full stack of driving tasks with graph-structured logical dependencies.
准确来讲,这个“全栈”指的是 Perception Prediction Planning 三项工作,而且组织方式是图结构(想起来了 nuScenes 数据集令人痛苦的图结构)
关于这个图结构,原仓库里有一个视频:在github观看 直接下载
The most exciting aspect of the dataset is that the questions and answers (
QA pairs) are connected in a graph-style structure, with QA pairs as every node and potential logical progression as the edges. The reason for doing this in the AD domain is that AD tasks are well-defined per stage, from raw sensor input to final control action through perception, prediction and planning.
Its key difference to prior VQA tasks for AD is the availability of logical dependencies between QAs, which can be used to guide the answering process. Below is a demo video illustrating the idea.
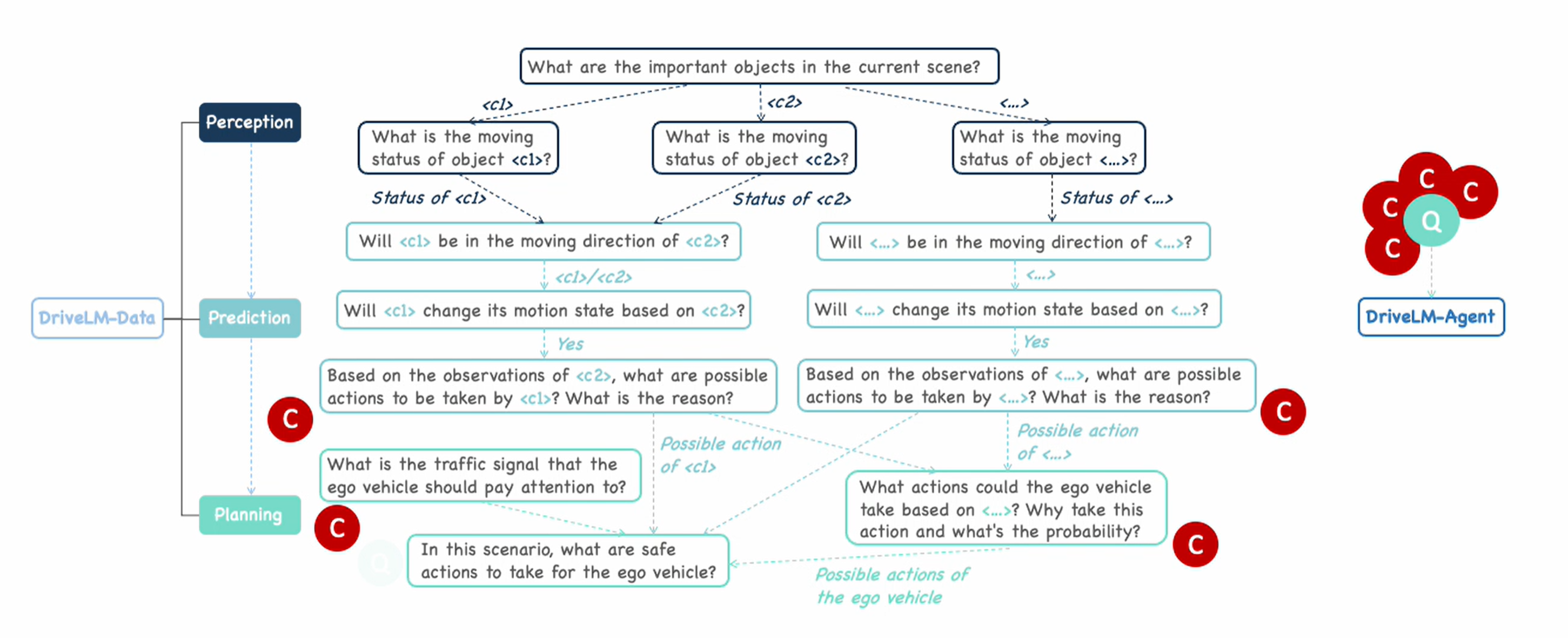
在 perception 的 Q-A 对中,对所有关心的物体的运动状态进行发问,获取运动状态;在 prediction 中依据 perception 问出来的 condition 预测它们的行为;接着再利用 perception 这里问出来的结论进行 plan。
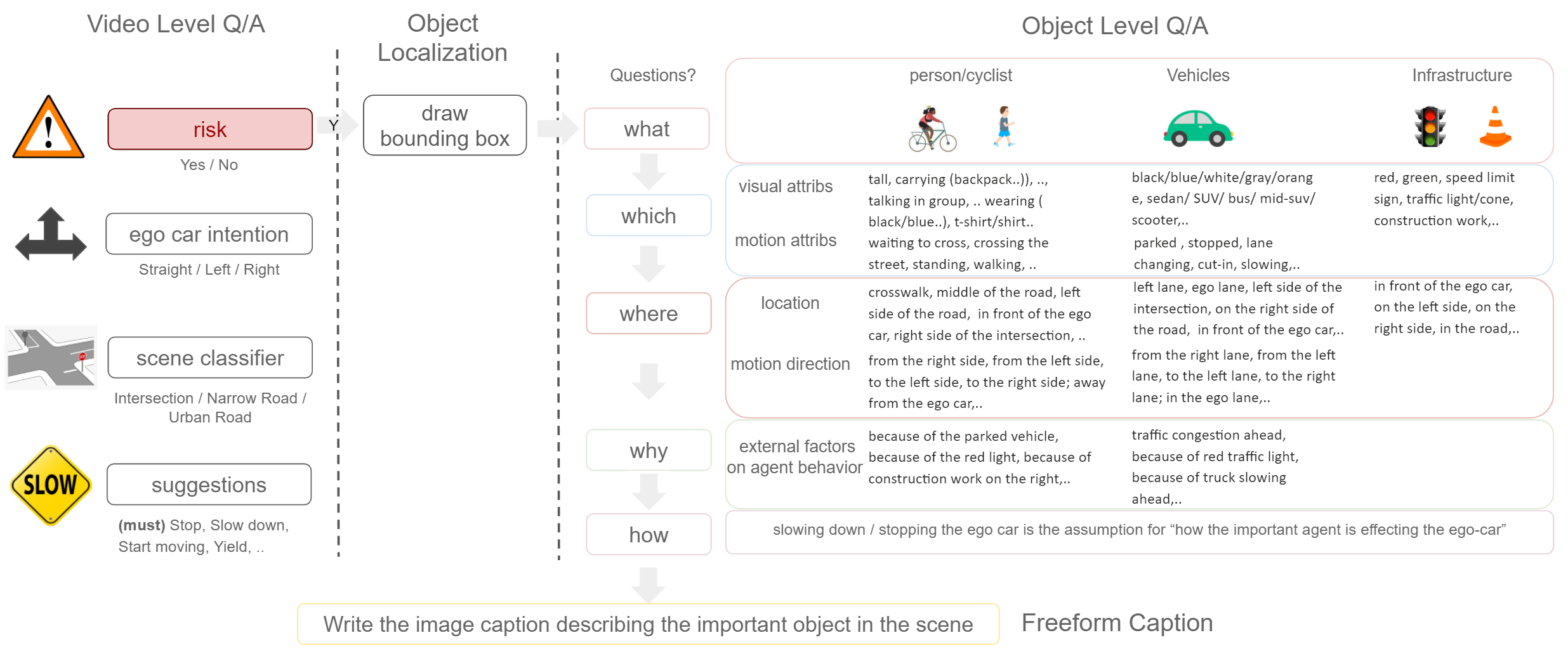
DRAMA (2023) (VQA)
和 HAD 一样又是 honda 的工作。链接:https://usa.honda-ri.com/drama
这个数据集是由很多两秒钟的视频片段组成的,在东京收集。
输入是视频、CAN控制信息、IMU信息;
标注是 Video-levelQ/A, Object-level Q/A, Risk object boundingbox, Free-form caption, and separate labelsfor ego-car intention, scene classifier and suggestions to the driver.
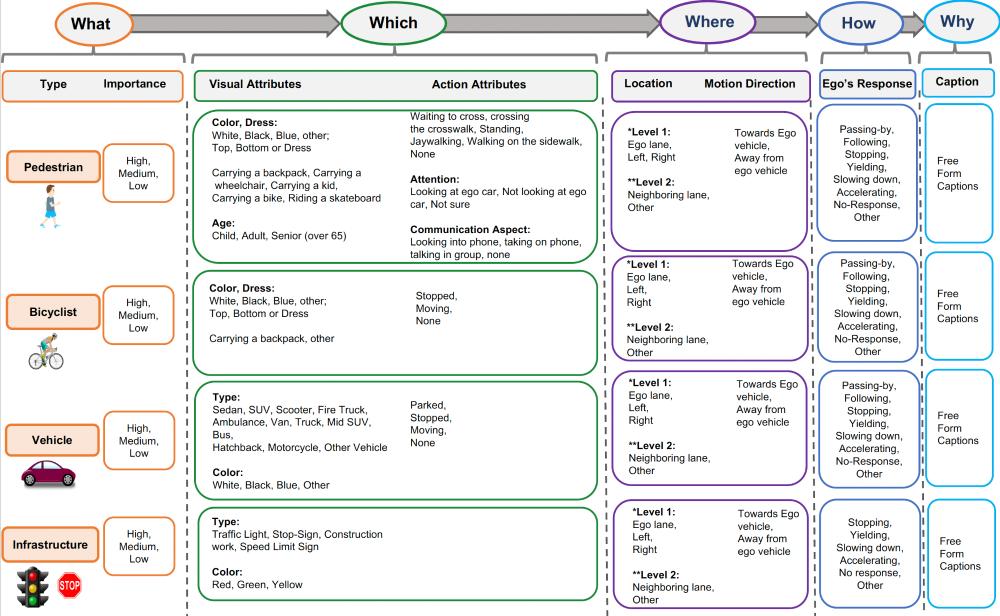
Rank2Tell (2023) (Perception + VQA)
又是 honda 的工作,链接:https://usa.honda-ri.com/rank2tell
20秒的116个片段,10fps(有点小啊),
输入:图像,LiDAR,GPS;
标注:Video-level Q/A, Object-level Q/A, LiDAR and 3D bounding boxes (with tracking), Field of view from 3 cameras (stitched), important object bounding boxes (multiple important objects per frame with multiple levels of importance-High, Medium, Low), free-form captions (multiple captions per object for multiple objects), ego-car intention.
NuPrompt (2023) (Perception)
链接:https://github.com/wudongming97/Prompt4Driving
从名字就能看出来基于 nuScenes,当然下面那个也是(事实上从论文的引用情况来看,NuScenes-QA 早于 NuPrompt)。值得一提的是这个数据集的生成用上了 ChatGPT-3.5,有一个根据描述不断取交集的过程(根据不同的prompt组合出query),在论文里有所体现。相较于其他数据集,这个数据集有利于模型从跨场景的信息中学习(论文里是这么说的?),提高复杂情形下的理解能力。
We assign a language prompt to a collection of objects sharing the same characteristics for grounding them. Essentially, this benchmark provides lots of 3D instance-text pairings with three primary attributes: ❶ Real-driving descriptions. Different from existing benchmarks that only represent 2D objects from modular images, the prompts of our dataset describe a variety of driving-related objects from 3D, looking around, and long-temporal space … ❷ Instance-level prompt annotations. Every prompt indicates a fine-grained and discriminative object-centric description, as well as enabling it to cover an arbitrary number of driving objects. ❸ Large-scale language prompts. NuPrompt is comparable to the largest current dataset in terms of the number of prompts, i.e., including 35,367 language prompts.
NuScenes-QA (2023) (VQA)
竟然是复旦,链接:https://github.com/qiantianwen/NuScenes-QA
这个就很直观了,从标题就可以看出是基于 nuScenes 数据集的 VQA。
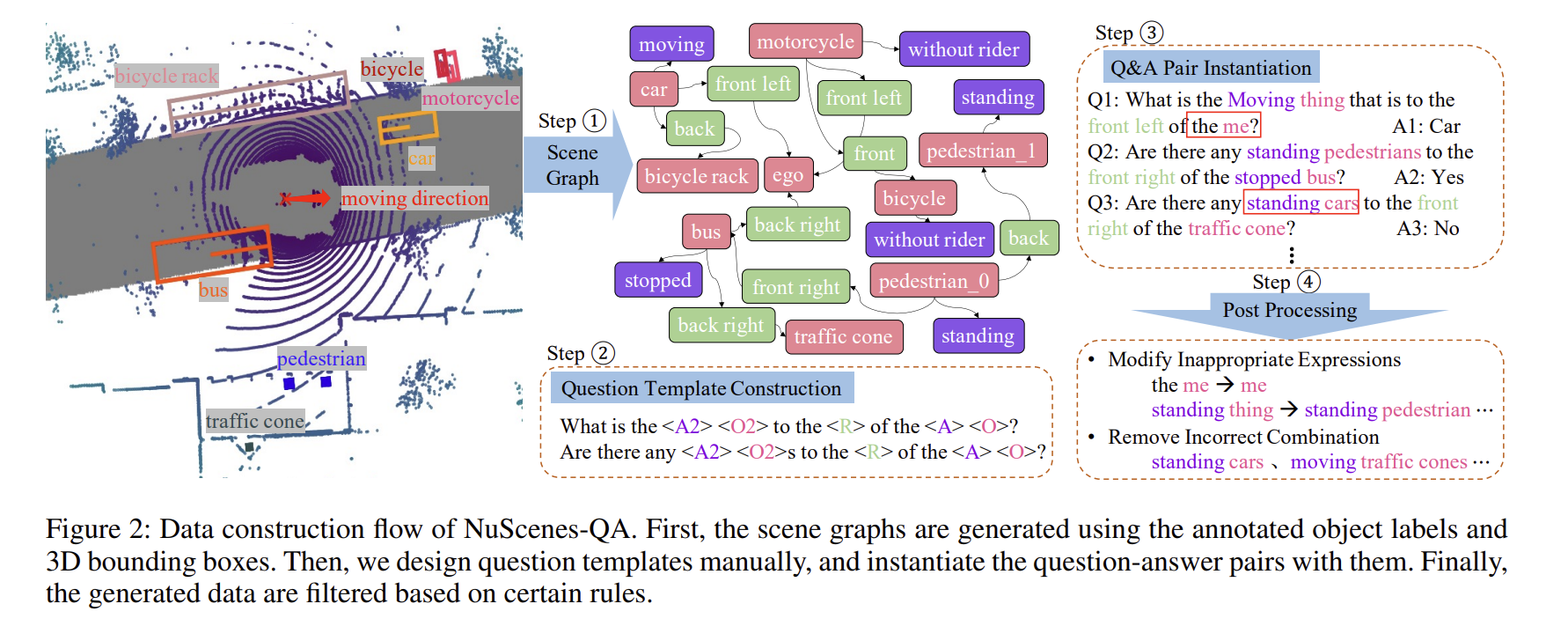
Reason2Drive (2023) (Perception + Prediction + VQA)
竟然还是复旦。不得不说复旦做的自动驾驶数据集还是挺多的。
链接:https://github.com/fudan-zvg/Reason2Drive
超级缝合加大版,用了 nuScenes,Waymo,ONCEA 这些数据集进行增广标注。之后 “parse their comprehensive object metadatas into JSON-structured entries. Each object entry contains various details pertaining to its driving actions.” 有了这些 metaData,就可以在多种任务的情况下,基于大语言模型进行增广,获得 QA-pair。

感觉基于大语言模型的 QA-pair 生成基本都是这种套路,对于这种数据的增广,LLM 还是比较高效的。想到自己之前做 iris 的数据集的时候也是这么干的(
LingoQA (2023) (VQA)
链接:https://github.com/wayveai/LingoQA
一个大规模的VQA工作,标注上把GPT、人工以及各种方式全用上了。手笔最大的一集。
比较有意思的是它还包括了 Lingo-Judge,可以给LLM在自动驾驶任务中问题生成的结果打分(correctness,0-1取值)。
NuInstruct (2024) (Perception + Prediction + VQA)
链接:https://github.com/xmed-lab/NuInstruct
这篇review过了,在这里:端到端自动驾驶笔记(最新进展篇) (meteorcollector.github.io)
这篇论文强调的是 Holistic,也就是整体、综合的。NuInstruct 比较关注整体的信息,分了17个子任务,涉及时间和空间上的组合、多视角等等信息。并且分了不同的类别:
In our research, we propose an SQL-based approach for the automated generation of four types of instruction-follow data, namely: Perception, Prediction, Risk, and Planning with Reasoning.
数据格式示例:
Train
{
'task': ..., # the task type, e.g., risk-overtaking
'qa_id':..., # QA pairs ID
'img_path':..., # image path list for a video clip
'Question':...., #
'Answer':...,
'sample_list':.... # sample token list of corresponding images in NuScense
}
OpenDV-2K (2024) (Perception + Prediction + VQA)
链接:https://github.com/OpenDriveLab/DriveAGI
究极巨大数据集。including 1747 hours from YouTube and 312 hours from public datasets, with automatically generated language annotations to support generalized video prediction model training. 事实上因为太大了,在 readme 上提出了建议:It's recommended to set up your experiments on a small subset, say 1/20 of the whole dataset
GenAD 本身是做世界模型 (World Model) 的工作,所以大规模的带标注的视频确实是这样的生成工作所需要的。
Perception
以下论文我个人的阅读顺序是引用数从高到低,由细到粗。
Language Prompt for Autonomous Driving
todo
Hilm-d: Towards High-Resolution Understanding in Multimodal Language Models for Autonomous Driving
todo
Mtd-gpt: A multi-task decision-making gpt model for autonomous driving at unsignalized intersections
todo
Planning & Control
Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles
todo
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving (13 Oct 2023)
链接:https://arxiv.org/abs/2310.03026
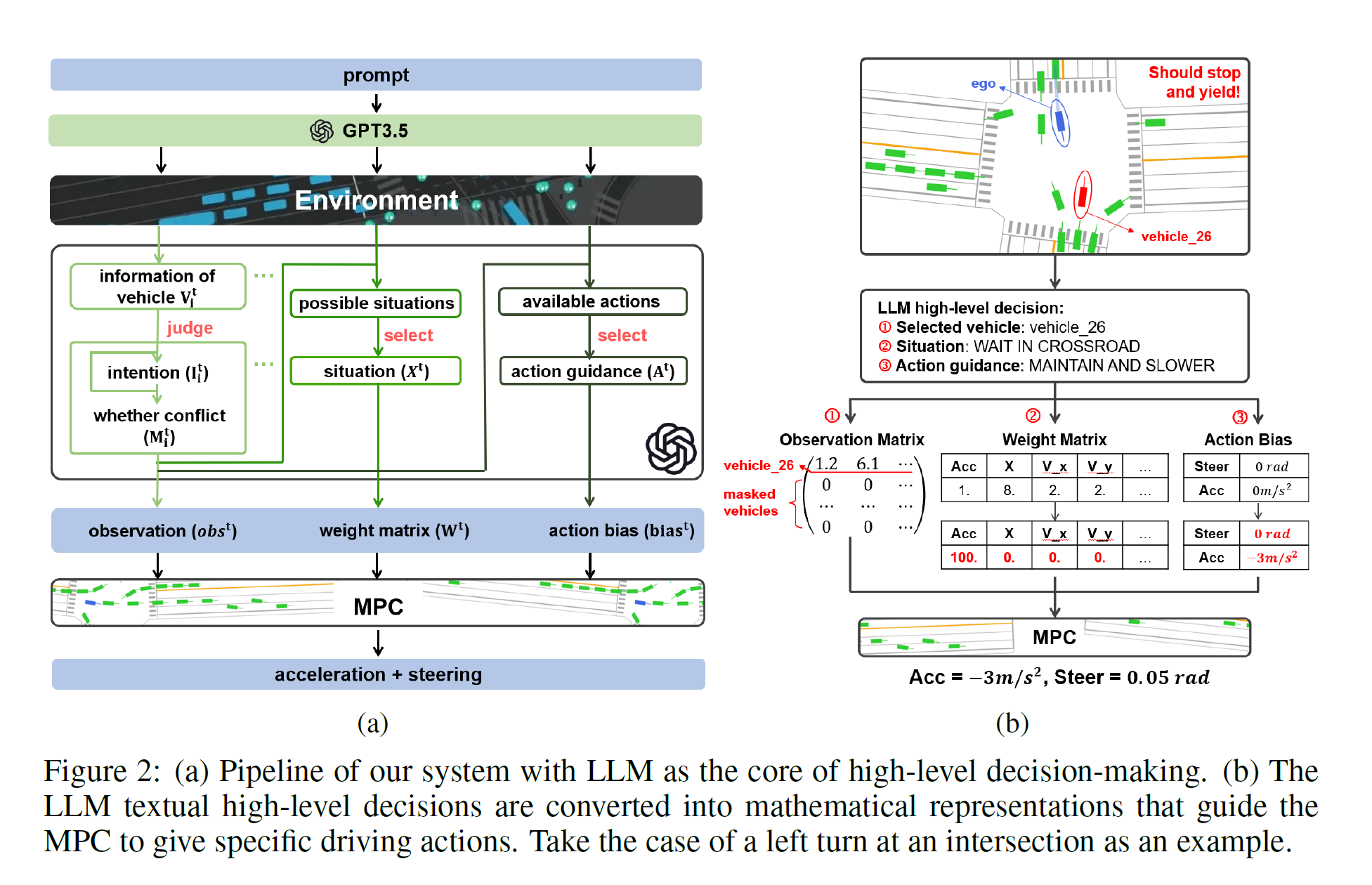
这篇文章里,大语言模型并不涉及 perception 方面的内容,只做 prediction 和 planning。所以说并不是一个“端到端”的工作。perception 的结果需要直接输入,看论文的话需要每个 vehicle 的运动信息。
模型结构
From left to right, the LLM proceeds sequentially: 1) identifies the vehicles requiring attention, 2) evaluates the situation, and 3) offers action guidance. Then the system transforms these three high-level textual decisions into mathematical representations, namely the observation matrix, weight matrix, and action bias. These elements serve as directives for the bottom-level controller, the MPC, instructing it on specific driving actions to be taken. These elements serve as directives for the bottom-level controller, the MPC, instructing it on specific driving actions to be taken.
和 GPT-Driver 类似,也是分步走的工作。这里比较有意思的是,对于每一步(perception后的注意力分配、prediction、planning)工作,模型要把它们转化为数学表示(observation matrix 用于指示当前需要观测的目标, weight matrix 用于指示当前采取的动作的weight(调整策略优先级), action bias(控制车辆动作即转向角和加速度))。MPC 是 Model Predictive Control 即模型预测控制,LLM 是通过调整 MPC 模型的参数来发挥作用的,换句话说,底层模型是 MPC,LLM 在这里只是它的一个模块。
MPC
The MPC solves a finite-time open-loop optimization problem online at each moment, based on the current measurement information obtained, and applies the first element of the resulting control sequence with the lowest cost to the controlled vehicle.
“MPC基于当前获取的测量信息,在每个时刻在线求解有限时间的开环优化问题,并将生成的控制序列中代价最低的第一个控制量应用于被控车辆。”

MPC模型的损失函数基于马尔可夫决策过程的累计误差,使用 L2 度量来计算期望值与GT之间的差距。虽然没有细研究这个模型,但是从公式上可以看出来,通过调整 $w$ 来改变 cost function,是可以改变不同策略的优先级的。这就是 LLM 发挥作用的地方。
LLM
LLM 则使用了 promt engineering 的方法进行使用。相较于 GPT-Driver,LanguageMPC 的步数更多一些。三个P都分别使用了不同的 thought chain 来引导回答。LLM 的框架用的是 LangChain。

验证方式
在论文里与 LanguageMPC 同台比较的是基于强化学习的方法和裸MPC。数据使用的是 IdSim ,指标是“Collision(每200秒发生撞击的概率), Fail(每200秒无法达到目标点的概率), Inefficiency(度量了当前车速和能达到的最大车速之间的差距), Time(到达目标点的时间), Acc Penalty, Dist Penalty(这些是看ego-vehicle离其他车辆有多近,越近越不安全), Overall Cost(综合指标)”
Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles
todo
DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models (22 Feb 2024)
链接:https://arxiv.org/abs/2309.16292
Drawing inspiration from the profound question posed by LeCun (2022): “Why can an adolescent learn to drive a car in about 20 hours of practice and know how to act in many situations he/she has never encountered before?”, we explore the core principles that underlie human driving skills and raise a pivotal distinction: human driving is fundamentally knowledge-driven, as opposed to data-driven.
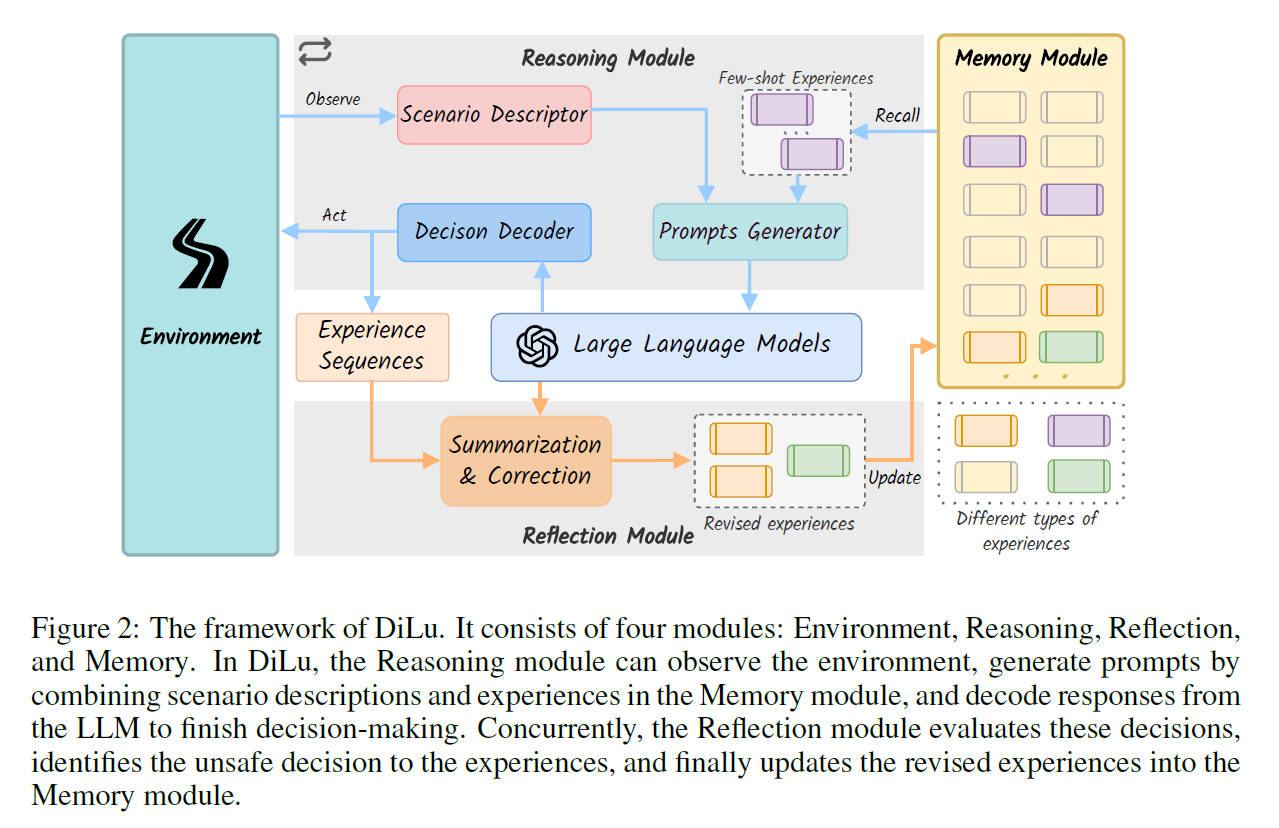
在观察环境信息后,当前环境信息和 Memory Module 共同向 Prompt Generator 输入信息来驱动 LLM 产生决策,Decision Decoder(图里打错了,捉虫)解析 LLM 给出的结果来进行 Action,这次的 Action 再输入给 Reflection 模块,评估这次做得安全不安全,再更新 Memory Module。
Memory Module
Memory Module 存储的是自然语言。
The memory stored in the memory module consists of two parts: scene descriptions and corresponding reasoning processes. The scene description provides a detailed account of the situation, serving as the key to the memory module for retrieving similar memories. The reasoning process, on the other hand, records the appropriate method for handling the situation.
同时,对 scene 的描述会被编码成向量称为 memory 的 key。这样,后续访问 memory 进行 recall 的时候,可以用这个向量的距离度量找到之前遇到过的最相似的情景,将这些情景代入大语言模型作为 few-shot 的前置。(第一次看还是挺奇妙的,我一打眼没看出来memory信息要怎么用到大语言模型里面,看过之后觉得 few-shot 也算是一个理所当然的处理方式。不过这样会不会导致推理时间增加……?)
Reasoning Module
首先,得到感知信息后进行 encode;然后从 memory module 里面找到最相近的情景进行 recall;然后利用 memory 的信息先做个 few-shot,做出 prompt 喂进 LLM;LLM 做出自然语言的回答,然后把它 Decode。
Reflection Module
reflection module 也是用上了 LLM 来评估模型是不是做了正确的决定,如果不对就进行修正。这些内容被整合之后塞进 memory module。
验证方式
为了验证 memory module 的有效性,分别对 0-shot (没有用 memory),1-shot,3-shots,5-shots 的情况进行了检验(应该每次使用多少个相近情形辅助LLM),而且将memory module的容量设置成 5,20,40 分别进行了检验。关于往 memory module 里放什么样的 experience 也是有研究的。实验结果说明 只放入成功经验的效果 < 只放入 revise 过的失败经验的效果 < 两种都放——最兼听则明的一集。
数据分两部分,一部分 GRAD 生成的内容(模拟测试), 一部分是 Highway-env 和 CitySim 两个数据集的现实数据。
测试指标是 SR (Success Rate): We defined the success rate (SR) as driving without any collision for 30 decision frames.
LMDrive: Closed-Loop End-to-End Driving with Large Language Models
这篇看过了,详见 端到端自动驾驶笔记(最新进展篇) (meteorcollector.github.io)
A language agent for autonomous driving
todo
GPT-Driver: Learning to Drive with GPT (5 Dec 2023)
链接:https://arxiv.org/abs/2310.01415
赵行的一篇,通篇没什么图片,看得我文字恐怖谷效应犯了。还有一大堆用公式形式化说明的内容,maths speak louder than words 吧大概。这篇着重关心的是 Planning 方面。
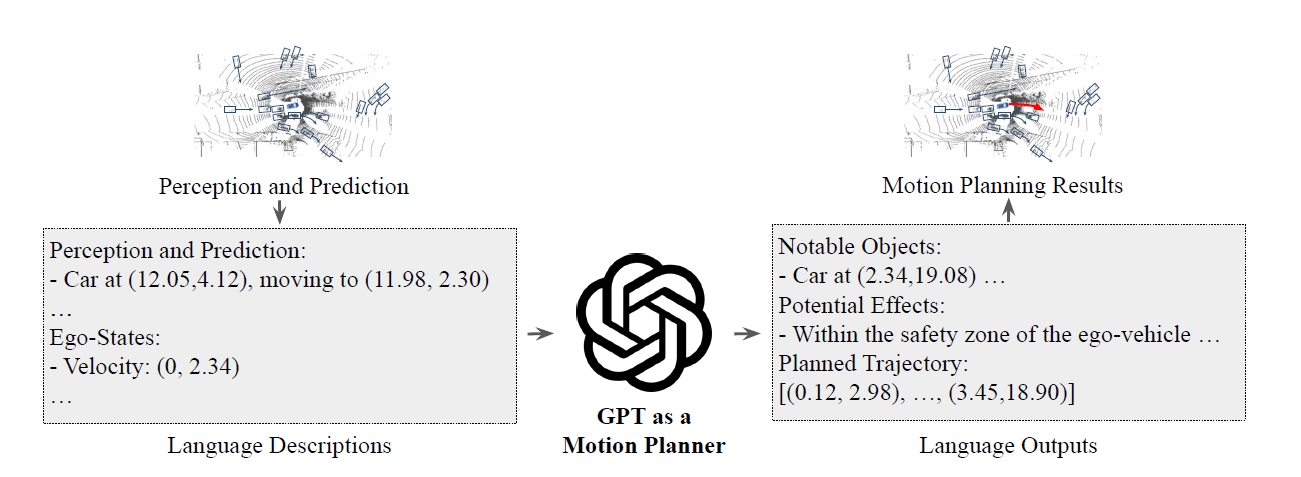
The crucial insight of this paper is to transform motion planning into a language modeling problem. Given a driving trajectory $\mathcal{T}$, we can represent it as a sequence of words that describe this trajectory:
$$\mathcal{T} = K(\{(x_1, y_1), \cdots, (x_{t}, y_{t})\}) = \{w_1, \cdots, w_n\},$$
where $w_i$ is the $i$-th word in this sequence. Please note that each coordinate value $x$ or $y$ in Equation can be freely transformed into a set of words ${w}$ using a language tokenizer $K$.
这块算是从理论上阐释了用自然语言模型做路径规划的可行性吧。
模型结构
GPT-Driver 得到路径的步骤是这样的(“novel prompting-reasoning-finetuning strategy”):
- 用 GPT 的 tokenizer $K$ 把观测输入 $\mathcal{O}$ 和 ego-state $\mathcal{S}$ 转换成为 language prompt (不是,prompt 不还是自然语言吗?这块 tokenize 成啥了啊,我看到 tokenize 还以为和一些多模态模型一样将其他模态的信息编码。而且论文3.3部分的 prompting 子部分也确实说明了他们确实是直接把感知输入转化成自然语言描述进行处理的,非常直接。原文:we resort to the parameterized representations of observations and ego-states and convert them into language descriptions,感觉还是很 prompt engineering)。

- 将 prompt 喂给 GPT3.5,记为
$F_{GPT}$,让语言模型根据 prompt 中的自然语言描述出 trajectory。这一步是 Reasoning:一步一步思考,给出预测的路径。现在用分模块端到端模型的视角看,第一步包含了 perception 比较后期和prediction的部分,后两步都属于 planning。实际上就是让大语言模型一步步干活——通过少量对话,可能大语言模型并不能立刻给出准确的答案,但是分成一个个子任务循序渐进,就可以让大语言模型以我们指定的逻辑链条进行推理,给出一个比较 reasonable 的答案。
In particular, we summarize the chain-of-thought reasoning process in autonomous driving into $3$ steps: First, from the perception results, the motion planner needs to identify those critical objects that may affect its driving dynamics. Second, by analyzing the future motions of these critical objects from the prediction results, the planner should infer when, where, and how this critical object may influence the ego vehicle. Third, on top of the insights gained from the previous analyses, the planner needs to draw **a high-level driving decision **and then convert it into a planned trajectory.

- We employ a simple finetuning strategy using the OpenAI fine-tuning API. 微调这个自然语言描述出的结果,使它与人类司机的驾驶轨迹接近。轨迹是直接从人类驾驶数据获得的,对于 reason-chain,用了一个 rule-based 的方法来获得 Ground Truth:直接计算车辆应该有的速度,关键物体的识别就是计算出与预测路径重合的物体。
总地来看,引用论文里的公式,就是:
$$\{ \mathcal{T}, \mathcal{R} \} = F_{GPT}(K(\mathcal{O}, \mathcal{S}))$$
验证方式
由于是 planning 工作,使用的是开环 nuScenes,L2 + Collision,无需多言。从表上看,GPT-Driver 的表现比 Uni-AD 还好,有些惊艳。不过由于 OpenAI 的 API 是纯黑盒,所以也并不知道这个模型的推理时间是多少,有待以后再验证吧。
Drivelm: Driving with graph visual question answering
todo
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model (14 Mar 2024)
链接:https://arxiv.org/abs/2310.01412
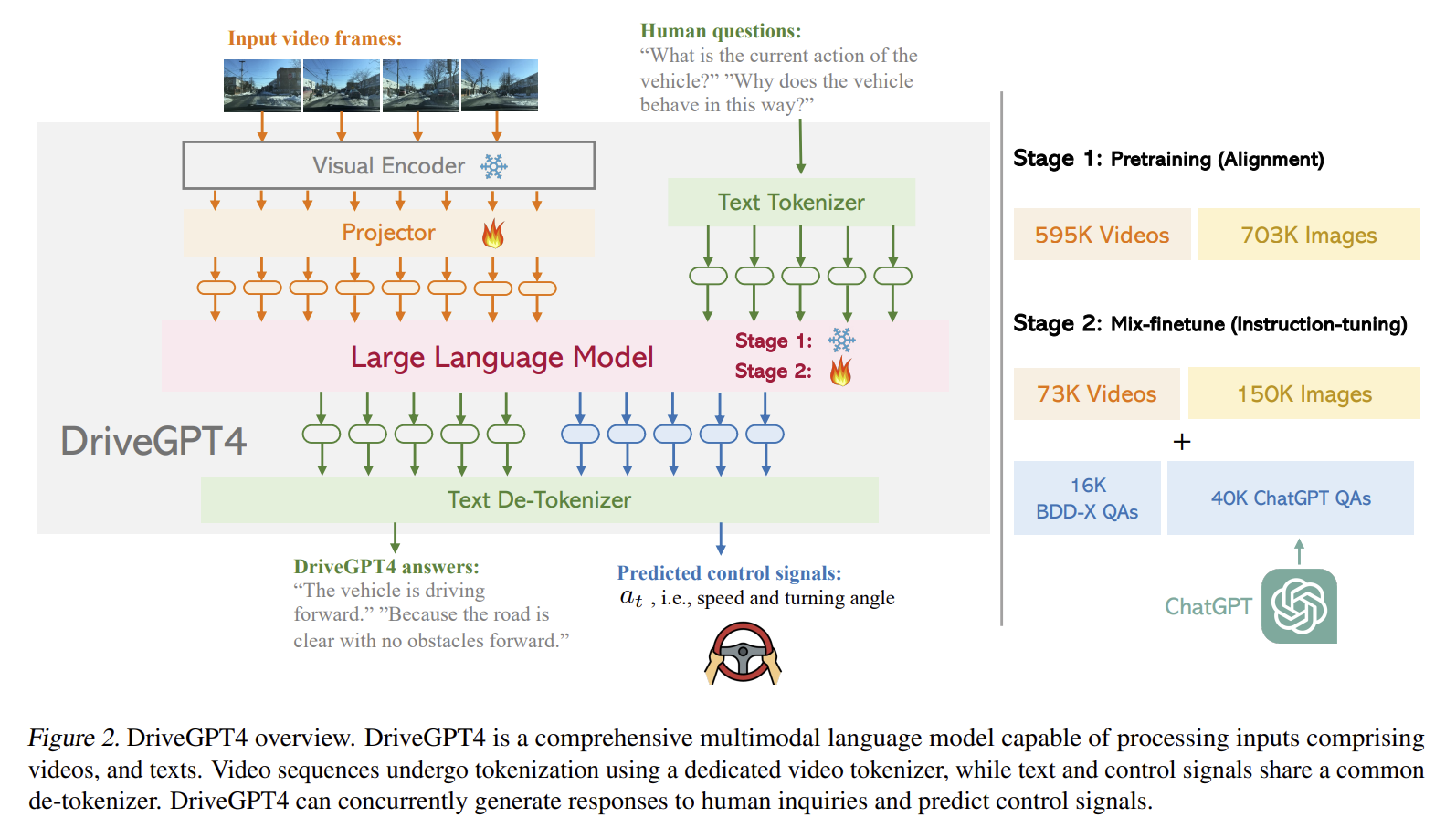
数据准备
这篇文章的数据集是以 BDD-X 为基础的,作者觉得 BDD-X 太机械了而且包含的信息少,因此使用 GPT-4 增广了 Q-A 对(we create our own dataset based on BDD-X assisted by ChatGPT)。这一步处理在原文中是这样写的:
To address the aforementioned issue, ChatGPT is leveraged as a teacher to generate more conversations about the ego vehicle. The prompt generally follows the prompt design used in LLaVA. (提示符通常遵循LLaVA中使用的提示符设计)To enable ChatGPT to “see” the video, YOLOv8 (Reis et al., 2023) is implemented to detect commonly seen objects in each frame of the video (e.g., vehicles, pedestrians) (为了使ChatGPT能够“看到”视频,使用了YOLOv8 (Reis et al., 2023)来检测视频每帧中常见的物体(例如车辆、行人))。Obtained bounding box coordinates are normalized following LLaVA and sent to ChatGPT as privileged information. (得到的边界框坐标按照LLaVA进行归一化(见下),并作为特权信息发送给ChatGPT)In addition to object detection results, the video clip’s ground truth control signal sequences and captions are also accessible to ChatGPT. 除了目标检测结果外,ChatGPT还可以访问视频片段的ground truth和标注信息。Based on this privileged information, ChatGPT is prompted to generate multiple rounds and types of conversations about the ego vehicle, traffic lights, turning directions, lane changes, surrounding objects, spatial relations between objects, etc. 基于这些特权信息,ChatGPT可以生成关于ego vehicle、交通信号灯、转弯方向、车道变化、周围物体、物体之间的空间关系等多轮和类型的对话。
所谓按照LLaVA进行归一化应该按照LLaVA论文中生成数据的方式整理格式。在 LLaVA的训练过程中,先通过 vision model 得到 context,原论文的示例:Context type 1: Captions A group of people standing outside of a black vehicle with various luggage. Luggage surrounds a vehicle in an underground parking area People try to fit all of their luggage in an SUV. The sport utility vehicle is parked in the public garage, being packed for a trip Some people with luggage near a van that is transporting it. Context type 2: Boxes person: [0.681, 0.242, 0.774, 0.694], backpack: [0.384, 0.696, 0.485, 0.914], suitcase: … 然后再输入 GPT-4 来增广 Q-A 对,让 GPT4 扮演教师的角色。
总而言之,训练数据格式是这样的:

模型结构
经典的把一切输入tokenize,concatenate,然后塞入大语言模型。
Video
DriveGPT4 要输入视频,使用的视频 tokenizer 是 Valley。
论文原文:
Let the input video frames be denoted as $V = [I_1, I_2, \ldots, I_N]$. For each video frame $I_i$, the pretrained CLIP visual encoder (Radford et al., 2021) is used to extract its feature $F_i \in R^{257\times d}$. The first channel of $F_i$ represents the global feature of $I_i$, while the other 256 channels correspond to patch features of $I_i$. For succinct representation, the global feature of $I_i$ is denoted as $F^G_i$ , while the local patch features of $I_i$ are represented as $F^P_i$ . The temporal visual feature of the entire video can then be expressed as:
$$T = F^G_0 \oplus F^G_1 \oplus \ldots \oplus F^G_N$$
where $\oplus$ denotes The spatial visual feature of the whole video is given by:
$$S = \mathrm{Pooling}\left(F^P_0, F^P_1, \ldots, F^P_N\right)$$
where $\mathrm{Pooling}(\cdot)$ represents a pooling layer that convert $N$ features into a single feature tensor for memory efficiency. Ultimately, both the temporal feature $T$ and spatial feature $S$ are projected into the text domain using a projector.
Text and control signals
为了进行自然语言问询和控制信号的预测,控制信号也要被输入,文中说是“与文本类似”的处理方法。
训练过程
这么大的模型没办法整体完全训练。于是很常见地分为了两步:
Pretraining
这一步 CLIP 和 LLM 被冻结,只有 projector 被训练。
使用的数据是 593K image-text pairs from the CC3M dataset and 703K video-text pairs from the WebVid-2M dataset (Bain et al., 2021). 我看了一下,前者是各种图片的描述,后者是一些 vision q-a 对,是针对视频的。在我看来预训练阶段是对 perception 部分的先行训练。
Mix-finetune
在这一阶段,projector、LLM 都被训练,目的是 “enable DriveGPT4 to understand and process domain knowledge”。这一步就用到了数据准备部分生成的数据了,一共 56K;同时还使用了 223K general instruction-following data generated by LLaVA and Valley。The former ensures that DriveGPT4 can be applied for interpretable end-to-end autonomous driving, while the latter enhances the data diversity and visual understanding ability of DriveGPT4.
验证方式
Interpretable AD
Ground Truth 用的主要是 BDD-X,因为“基本没有别的可用”。在这篇文章之前,SOTA方法是 ADAPT ,因此文章里主要将 DriveGPT4 和 ADAPT 做对比。采用的指标是 NLP 那边比较常用的,包括 CIDEr,BLEU4,ROUGE-L。这三者的描述和实现可以参考 https://github.com/Aldenhovel/bleu-rouge-meteor-cider-spice-eval4imagecaption ,都是衡量和 Ground Truth 相似度用的,用来打分。
End-to-end Control
Ground Truth 仍使用 BDD-X 。衡量了控制信号(速度和转向角)的预测能力,使用的是均方误差($MSE$)和 threshold accuracy ($A_\gamma$)(the proportion of test samples with prediction errors lower than $\gamma$)
定性分析
剩下的就是一些定性的展示,比如和 GPT-4V 比一比理解能力之类,不在这里费笔墨了。
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving (13 Oct 2023)
链接:https://arxiv.org/abs/2310.01957
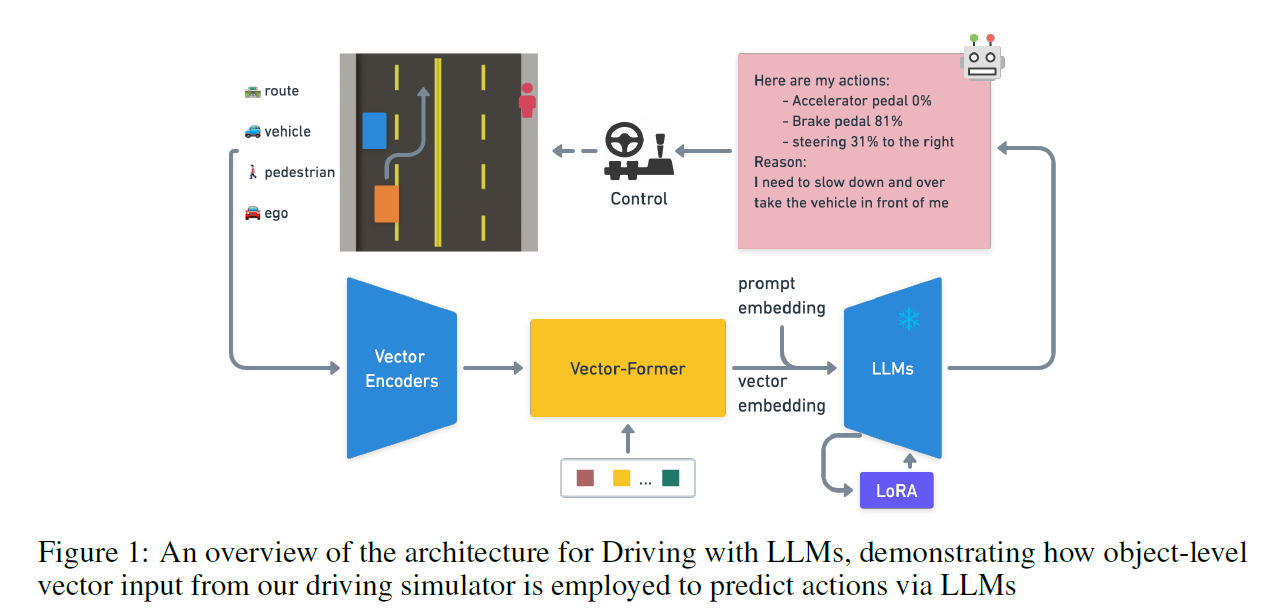
Wayve 的工作。
这项工作和其他不同的方面是先把感知结果输入喂给了 Vector Encoder,然后经过 Vector-Former 送入 LLM。LLM 本身不负责感知,只做下游的决策。因此不是端到端的工作。
而且这项工作只用到了二维俯视信息,而不是三维的。这样看来前面接一个 BEVFormer 就是完全体了?(
数据准备
用的是一个基于 RL 的 2D 模拟器来生成驾驶情形。强化学习方法用的是 PPO (Proximal Policy Optimization(还不懂,以后要看))。收集之后把 100K 的数据用来与训练,10K 去做 QA 标注和微调,1K 用来 evaluate。
收集到的数据包含了车辆、行人、ego-vehicle、路线的向量表示,以及 RL agent 在 reasoning 步骤产生的注意力和行动标注(其实就是 RL agent 的决策,在这里用 RL agent 来教会 LLM 怎么做决定)。之后用一个 rule-base 的方法 lanGen 来生成自然语言描述。
自动驾驶的 Q-A 数据集是使用 ChatGPT 来生成的。
训练过程
为了使训练一个 object-level vector modality (对象级别向量模态,可能就是用向量表示 perception 得到的二维要素,然后作为模态输入)的 LLM,作者用了两步来训练。第一步冻结 LLM,只训练 vector encoder 和 vector former 里面的那一大堆 transformer 。第二步训练 LLM 来做自动驾驶情形的 QA Task (DQA Task)。LLM 不是从头训练的,而是用 LoRA 微调。
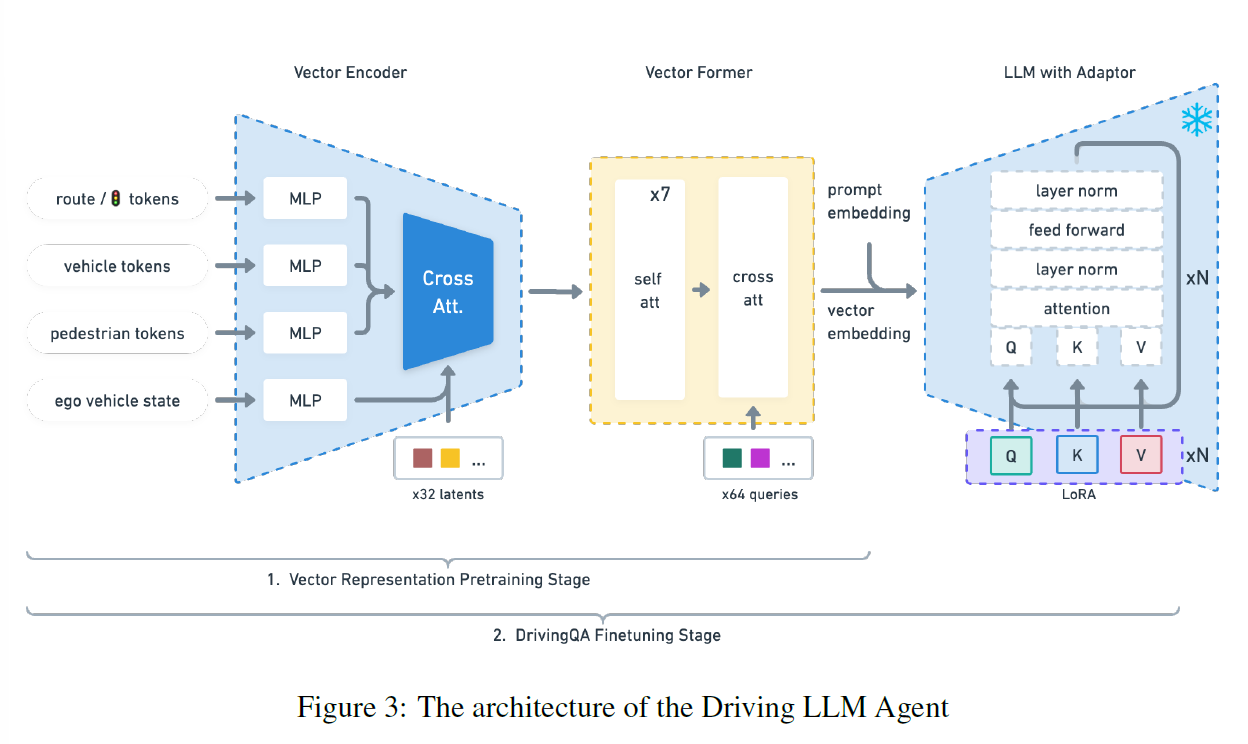
但是不管是第一步预训练还是第二步的整体训练,都是 end-to-end 训练的,并没有把模块分开训练(这里和 Wayve 的另外一个工作 GAIA-1 不一样,在那篇工作里,Encoder 是单独训练的。当然 GAIA 的规模大、流程长,端到端全训练不是很现实)。
第一步预训练使用的是 lanGen 产生的自然语言 caption,内容只包括 prediction 和 agent attention prediction——原因是要重点训练 vector transformer,让它们更好地表示感知信息。
第二步训练用 LoRA 微调时,使用的是 GPT 生成的 QA 对。
LLM 训练的损失函数一般就是交叉熵损失了。
验证方式
为了对比,使用了一个不用 LLM 的模型以及不进行预训练的模型和完全体模型进行对比。用的数据就是之前留出来的 evaluation set。
Perception and Action Prediction
评估了车辆和行人的 agent count 、交通灯的 accuracy 和 distance、加速度和方向盘方向这几项预测值的 MAE (Mean Absolute Error,平均绝对误差),以及评估 LLM 用的对 token 预测的交叉熵损失。
Driving QA
这里是用给答案打分的方式来评估的,有些玄学。一部分用GPT进行打分,另一部分由于“我们注意到GPT有些时候倾向于语法接近但是语义不接近的答案”,人工给230对随机QA对进行了打分。感觉这个评价标准有一些主观。
VLP: Vision Language Planning for Autonomous Driving
这篇看过了,详见 端到端自动驾驶笔记(最新进展篇) (meteorcollector.github.io)
Generation
Drivedreamer: Towards real-world-driven world models for autonomous driving
todo
GAIA-1: A Generative World Model for Autonomous Driving (29 Sep 2023)
链接:https://arxiv.org/abs/2309.17080
wayve的工作,Generative AI for Autonomy
由于既要理解又要生成,而且模态很多,这篇论文非常长。工作量也很大,做这种工作的研究机构的体量也就可想而知了。
模型结构
In this work we introduce GAIA-1, a method designed with the goal of maintaining the benefits of both world models and generative video generation. It combines the scalability and realism of generative video models with the ability of world models to learn meaningful representations of the evolution into the future. GAIA-1 works as follows. First, we partition the model into two components: the world model and the video diffusion decoder. The world model reasons about the scene’s high-level components and dynamics, while the diffusion model takes on the responsibility of translating latent representations back into high-quality videos with realistic detail.
也就是说,GAIA-1 先理解过去,再生成未来。话说现在生成式方向,diffusion 真的是压倒性的主流啊。
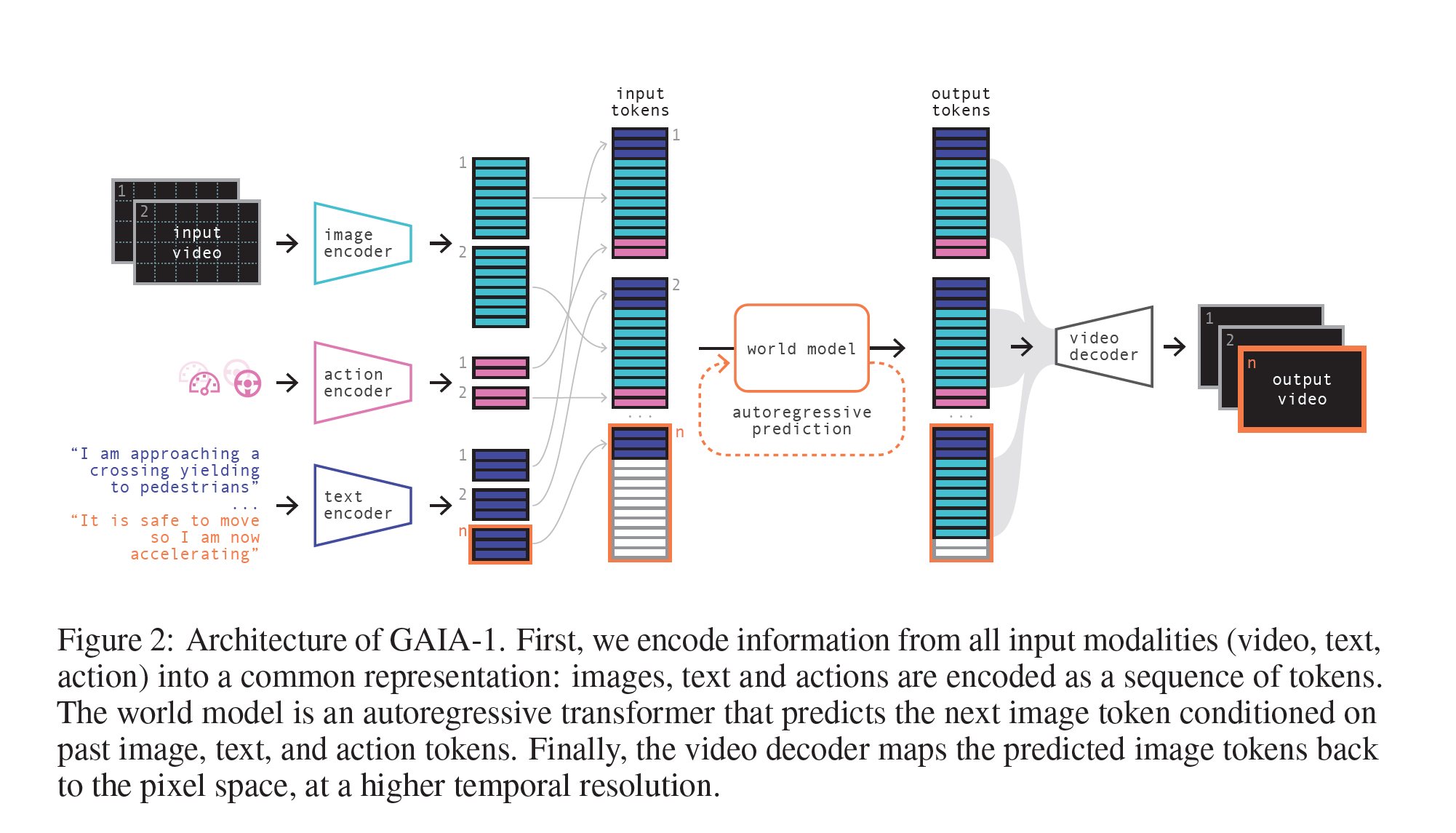
在输入方面,GAIA 有 Image、Text、Action 三个输入,分别 tokenize。
image 使用了一个预训练的 image tokenizer 进行编码,text 整合了自然语言和 action 的信息,action 的记录了当前的运动状态(速度和曲率)(说实话我觉得相较于其他某些论文采用偏角,还是曲率更好一些,毕竟偏角有些离散了)
对于每个时间点,三种不同模态的输入轮流进入输入序列,顺序是 文本 -> 图像 -> 动作,记作 $(\mathbf{c}_1, \mathbf{z}_1, \mathbf{a}_1, \ldots, \mathbf{c}_T, \mathbf{z}_T, \mathbf{a}_T)$
模型的主要成分有:
Image Tokenizer
为了减少计算量,需要进行图像的下采样。但是又不能把关键信息给压没,所以要 Guide the compression towards meaningful representations, such as semantics——向有意义的方向引导压缩,例如语义。在这里使用了将语义压缩进图片的 DINO 模型。
作者训练了一个专用的 Image Tokenizer,结构是 2D U-net。在单独对它进行训练时,需要有解码器,然后利用解码出来的结果计算损失函数,包括了 Image reconstruction loss、Quantization loss、Inductive bias loss 三种损失。
World Model
已知世界模型的输入是 $(\mathbf{c}_1, \mathbf{z}_1, \mathbf{a}_1, \ldots, \mathbf{c}_T, \mathbf{z}_T, \mathbf{a}_T)$ ,模型本身是 autoregressive transformer network that models the sequence input (对序列输入进行建模的自回归 transformer 网络),进行后续序列的预测。全文没有提到 LLM,但是这里其实就是 LLM:预测下一个 token。可能这就是为什么这篇文章能放到 LLM4Drive 的范围里吧。Loss Function 如下:
$$L_{\text{world model}} = -\sum^T_{t=1}\sum^n_{i=1} \log p(z_{t,i}\mid \mathbf{z}_{<t},z_{t,j<i},\mathbf{c}_{\leq t},\mathbf{a}_{<t})$$
(有点像最大似然)
这里还提到了一个 trick,We randomly dropout conditioning tokens during training so that the world model can do (i) unconditional generation, (ii) action-conditioned generation, and (iii) text-conditioned generation. 唉,手笔真大啊,一下子顾及到这么多功能,还都做出来了。
Video Decoder
因为视频信息是前后关联的,所以离散地提取每一帧图片的token并不合理,所以 decoder 必须能访问到时间上的信息。
A naive approach of independently decoding each frame-tokens to pixel space results in a temporally inconsistent video output. Modeling the problem as denoising a sequence of frames during the diffusion process, where the model can access information across time, greatly improves temporal consistency of the output video.
Video Decoder 使用了具有时间和空间注意力层的 3D U-Net。在训练过程中,使用的输入是之前 image tokenizer 的输出;推理时使用的是世界模型预测出来的未来 image 的 token。作者把它训练成了一个 image 和 video 都生成的模型:image 生成的训练提高单个帧的图像质量,video 生成的训练提高帧与帧之间的 consistency。
训练的时候还用到了 mask 掉不同位置的 image token 来训练多种生成任务的 trick。总之是一个 diffusion 的思路,以 image token 为输入,推理出一个去噪的过程。
视频解码器的 Loss Function 比较复杂:

数据准备
使用的是正宗老伦敦的 4700 小时驾驶数据。针对不同训练任务如何组织数据说得事无巨细。
训练过程
论文里详细讲了用什么练了多少步、练了多久。Loss Function 在上文已经齐备,所以这里不再细讲
Scaling
在 LLM 中有 Scaling Law,就是模型的规模越大、参数越多,效果越好。作者在 GAIA 上也发现了这一定律(GAIA 和 LLM 原理都差不多,有一样的规律也是自然),提出力气更大能飞出去的砖也更重。确实,但是现在这个模型已经很大了吧……
Magicdrive: Street view generation with diverse 3d geometry control
todo
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
这篇看过了,详见 端到端自动驾驶笔记(最新进展篇) (meteorcollector.github.io)
Question Answering (QA)
Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving’
todo
Drivelm: Driving with graph visual question answering
见上
Human-centric autonomous systems with llms for user command reasoning
todo
Evaluation & Benchmark
On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving
todo