
前情提要
“具身智能的切入点是灵活手”
为了明确未来的研究方向,需要对具身智能有一定了解。毕竟现在看来cv的未来还是与robotics结合的。
具身智能和自动驾驶差不多,最传统的思路还是模仿学习和强化学习。作为非ai专业学生,还是要补一补这方面的知识。
有两个比较好的学习资料,放在这里,以后要找时间啃下来:
LAMDA的模仿学习教程:Imitation_Learning.pdf (nju.edu.cn)
上交“强化学习”课程课本《动手学强化学习》:前言 (boyuai.com)
为了知道大家都在干啥,还是第一时间读一些论文。这些论文如果没有特别标注,都晚于2023年。(早于2024年中)
Definition from CMU
Robots that perceive, act and collaborate.
Embodied AI is the integration of machine learning, computer vision, robot learning and language technologies, culminating in the “embodiment” of artificial intelligence: robots that can perceive, act and collaborate.
Robotics, Embodied AI and Learning (REAL) hosts a team of researchers and scientists who are elevating the role of robots from tools to partners, working side by side with humans to solve complex real-world challenges.
Description from ACM
These foundational studies highlight three principles for developing EAI (Embodied Artificial Intelligence) systems. First, EAI systems must not rely on predefined, complex logic to manage specific scenarios. Second, it is essential that EAI systems incorporate evolutionary learning mechanisms, enabling them to adapt continuously to their operational environments. Lastly, the environment plays a pivotal role in shaping not just physical behaviors, but also cognitive structures.
https://cacm.acm.org/blogcacm/a-brief-history-of-embodied-artificial-intelligence-and-its-future-outlook/
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
这是比较早期(2022)年的工作 SayCan,主要由两部分组成:Say(大语言模型给出的方案)和 Can (基于强化学习的打分,给出feasible的行动方案)
输入输出
输入:
- 自然语言指令: 用户给出的描述任务的自然语言指令,可以是长期、抽象或含糊的。
- 技能集合(Skills): 机器人具备的一系列基本行为技能,如“拿起海绵”或“去桌子那里”。
- 环境状态: 机器人当前所处的环境状态,包括物体的位置、机器人的状态等。
输出:
- 行动序列: 机器人根据输入的自然语言指令和当前环境状态,通过模型处理后,输出一系列行动步骤,指导机器人完成任务。
模型结构
SayCan 模型结合了大型语言模型(LLMs)和预训练的技能(skills),通过以下组件实现:
- 大型语言模型(LLM): 用于理解高层次的指令,并生成可能的行动步骤的文本描述。这些模型能够提供任务的语义知识,但缺乏对物理世界的具体理解。
- 预训练技能(Skills): 机器人具备的一系列基本行为,如抓取、移动、放置物体等。每个技能都有一个与之关联的价值函数(affordance function),该函数评估在当前状态下执行该技能的可能性。
- 价值函数(Value Functions): 通过强化学习(RL)训练得到,用于评估在特定状态下执行特定技能的成功率。这些函数为语言模型提供了“现实世界”的锚定,使其能够根据机器人的实际能力选择可行的行动步骤。
- 行动选择机制: 结合语言模型生成的技能描述的概率和价值函数评估的执行概率,选择最有可能成功并推进任务完成的技能。
- 迭代执行与更新: 机器人执行选定的技能,然后根据执行后的环境状态更新语言模型的输入,继续选择下一个技能,直到任务完成。
我感觉比较玄乎的是强化学习的部分。先补一下强化学习然后回来看看吧。
LLM + Robotics
肯定会存在的一个方向,被吹成“最接近通用人工智能的”LLM,肯定是一个可行的技术路线,但是上限我觉得不好说。
Awesome 仓库:
PaLM-E: An Embodied Multimodal Language Model
究极多模态缝合,
“论文提出了一个具身多模态语言模型,通过将真实世界的连续传感器模态直接融入语言模型中,实现了单词和感知之间的联系。实验结果表明,PaLM-E可以处理来自不同观察模态的各种具身推理任务,并在多个实现上表现出良好的效果。最大的PaLM-E-562B模型拥有562亿个参数,除了在机器人任务上进行训练外,还是一个视觉语言通才,并在OK-VQA任务上取得了最先进的性能。”
实际上我觉得他这个在控制方面输出还是比较模糊的。
OK-VQA https://okvqa.allenai.org/ 是视觉语言的数据集,和 robotics 无关。
论文里对输出的描述是:
PaLM-E is a generative model producing text based on multi-model sentences as input. In order to connect the output of the model to an embodiment, we distinguish two cases.
在多模态问询方面,If the task can be accomplished by outputting text only as, e.g., in embodied question answering or scene description tasks, then the output of the model is directly considered to be the solution for the task.
在具身方面,Alternatively, if PaLM-E is used to solve an embodied planning or control task, it generates text that conditions lowlevel commands. In particular, we assume to have access to policies that can perform low-level skills from some (small) vocabulary, and a successful plan from PaLM-E must consist of a sequence of such skills.
实际上输出的仍然是 low-level 的自然语言指令。
评估其实也是一个令人头大的方面,在具身智能领域,还没有看到一个普适的评价标准。
在 perception 方面,测试方法已经很成熟了。
- 语言和视觉语言任务的基准测试:
- 除了机器人任务,作者还评估了PaLM-E在通用视觉语言任务上的性能,如视觉问题回答(VQA)和图像字幕生成。
- 使用了标准的基准测试,如OK-VQA、VQA v2和COCO字幕生成,来评估模型。
- 语言任务的基准测试:
- 评估了PaLM-E在多种自然语言理解和生成(NLU和NLG)任务上的性能,包括但不限于TriviaQA、Natural Questions、Lambada、HellaSwag等。
- 模型规模的影响:
- 研究了不同规模的PaLM-E模型(如12B、62B、540B参数版本)对性能的影响,以及模型规模对保留语言能力的影响。
但是在与具身有关的方面,它是这样做的:
以下是用于评估模型性能的具体方法:
- 任务和运动规划(TAMP):
- 在这个环境中,机器人需要根据自然语言指令来规划和执行一系列操作,例如抓取和堆叠物体。
- 评估指标包括规划成功率(模型生成的计划是否正确)和执行成功率(机器人是否能够成功执行计划)。
- 桌面推动任务:
- 在这个任务中,机器人需要根据指令推动桌面上的物体,例如将一个物体推到另一个相同颜色的物体旁边。
- 通过成功率来评估模型性能,即机器人是否能够根据指令正确地推动物体。
- 移动操作任务:
- 这个任务涉及更复杂的环境,机器人需要在厨房环境中执行一系列导航和操作任务,如从抽屉中取出物体并将其带给用户。
- 评估指标同样包括规划成功率和执行成功率,以及机器人在面对干扰时的鲁棒性。
- 多模态输入表示的比较:
- 作者比较了不同的输入表示方法(如标准ViT编码和对象中心ViT编码)对模型性能的影响。
- 通过在相同的任务上测试不同输入表示的模型,评估它们在具身任务中的有效性。
- 多任务训练的效益:
- 研究了在多种任务上共同训练模型是否能够带来性能提升,即所谓的“迁移学习”。
- 通过比较单一任务训练和多任务训练的模型在具身任务上的表现,评估多任务训练的效益。
- 少样本学习:
- 评估了PaLM-E在只有少量训练样本的情况下执行任务的能力,这在机器人领域尤为重要,因为相关数据通常较为稀缺。
- 通过在只有少量演示的情况下测试模型的性能,评估其在实际应用中的可行性。
- 与现有方法的比较:
- 将PaLM-E与现有的最先进视觉语言模型(如PaLI)和特定的机器人控制算法(如SayCan)进行了比较。
- 通过在相同的任务上比较不同方法的性能,评估PaLM-E在具身任务中的竞争力。
这个“完成任务的正确率”就很难说。一是这些任务到底有多难?二是除了“能不能做”,“完成得好不好”如何体现?
VoxPoser: Composable 3D Value Maps
重量级,李飞飞那边的工作。
解决的是 grounding 的问题,也就是如何把 LLM 的指令转化为实际动作。我觉得还是很重要的,感觉很多工作最后的输出也就是自然语言,没有把 action 落到实处。
- 核心思想:利用LLMs推断出语言条件下的可供性(affordances)和约束,并通过编写代码与VLMs交互,生成3D价值地图(value maps),将这些知识转化为机器人可感知的空间中的实体。
- 方法:通过生成Python代码,调用视觉API(如CLIP或开放词汇检测器)获取相关对象的空间几何信息,然后操作3D体素来在观察空间中指定奖励或成本。
- 应用:这些生成的价值地图作为运动规划器的目标函数,直接合成机器人轨迹,实现给定指令,无需额外的训练数据。
模型结构:
- 大型语言模型(LLM):
- 负责理解自然语言指令,并推断出任务相关的可供性(affordances)和约束。
- 利用其代码编写能力,生成Python代码以调用视觉API和执行数组操作。
- 视觉-语言模型(VLM):
- 负责处理视觉输入,如通过开放词汇检测器识别物体和获取空间几何信息。
- 3D价值地图:
- 由LLM生成的代码与VLM的输出相结合,形成3D价值地图,这些地图在机器人的观察空间中定义了任务的目标和约束。
- 运动规划器:
- 使用3D价值地图作为目标函数,通过零阶优化方法(如随机采样轨迹)合成机器人轨迹。
- 动态模型:
- 可选组件,用于在线学习环境的动态特性,特别是在涉及复杂接触交互的任务中。
输入:
- 自然语言指令:
- 用户给出的任务描述,如“打开顶部的抽屉并注意那个花瓶”。
- RGB-D观察:
- 机器人当前的三维环境观察,通常包括颜色和深度信息。
输出:
- 3D价值地图:
- 包括:
- 可供性地图:指导机器人动作的目标位置。
- 约束地图:定义了应避免的区域,如附近的花瓶。
- 旋转地图:指定末端执行器的朝向。
- 速度地图:指定动作的速度。
- 夹持器地图:控制夹持器的开闭状态。
- 包括:
- 机器人轨迹:
- 一系列6自由度末端执行器的关键点,用于执行任务。
工作流程:
- 指令解析:
- LLM解析自然语言指令,推断出任务的子步骤。
- 价值地图合成:
- LLM生成代码,调用VLM获取视觉信息,并操作3D数组生成价值地图。
- 轨迹规划:
- 运动规划器使用价值地图作为目标函数,规划机器人的轨迹。
- 执行与反馈:
- 机器人执行规划的轨迹,并通过感知模块反馈执行结果,用于动态模型的学习。
模型的评估在 Experiment and Analysis 方面,真实世界里和模拟环境里都做了。
- 真实世界实验:
- 使用Franka Emika Panda机器人在一个配置有日常物品的桌面环境中进行实验。
- 机器人配备有两个RGB-D相机,用于捕捉实时的三维环境信息。
- 选择的任务包括“移动并避开物体”、“设置桌子”、“关闭抽屉”、“打开瓶子”和“清扫垃圾”等。
- 模拟环境实验:
- 在模拟环境中创建了一个包含13个任务的实验套件,这些任务在模拟的厨房环境中进行。
- 任务设计为包含可随机化属性的模板指令,以测试模型对已见过(seen)和未见过(unseen)属性的泛化能力。
但是问题是没有什么比较统一的指标(目前还没见到哪个论文里有),每项工作都玩自己的,有点难以捉摸。
SAPIEN: A SimulAted Part-based Interactive ENvironment
2020年的关于模拟环境的文章,voxposer用的simulation就是这个。这个环境建构得非常细致,interaction需要比较详细的。对于 voxposer 这种输出详细规划路线的模型是比较合适的,但是对于输出 low-level natual language 的模型,是不是还是不太行呢?
March in Chat: Interactive Prompting for Remote Embodied Referring Expression
自所的工作,这项工作主打一个 remote,即机器人做的工作是在一个比较大的环境里进行的,所以定位目标点并进行寻路是它的主要任务。这个模型的输出也是较为抽象的,主要还是只提供了一个寻路。
REVERIE也是它们的工作,论文名称是 REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments,专长于远程寻路拿取物体的 task。march in chat 可以视作这篇工作的延伸。
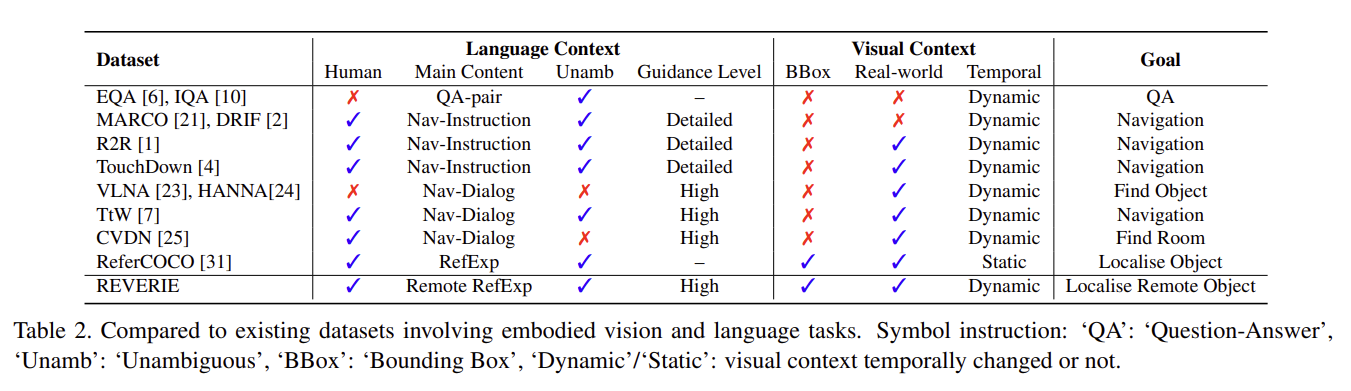
有一说一 navigation 的数据集还是有不少的(来自 REVERIE 论文):
主要贡献和方法:
- 交互式提示(Interactive Prompting):MiC 模型通过与大型语言模型(LLM)进行实时对话来动态规划导航步骤。这种方法允许智能体根据当前的视觉观察和环境反馈调整其导航策略。
- Room-and-Object Aware Scene Perceiver (ROASP):为了使 LLM 能够更好地理解环境并做出适应性规划,作者提出了 ROASP 模块。该模块利用 CLIP 模型来预测智能体当前所在房间的类型以及可见的对象,从而为 LLM 提供环境上下文信息。
- 两个规划模块:
- Goal-Oriented Static Planning (GOSP):在任务开始时,使用 GOSP 模块让 LLM 识别指令中的目标对象并推断可能的位置。
- Scene-Oriented Dynamic Planning (SODP):在导航过程中,根据 ROASP 提供的环境反馈,使用 SODP 模块生成详细的步骤指导。
- 实验结果:在 REVERIE 基准测试中,MiC 模型在所有指标上均取得了新的最佳性能,特别是在 SPL 和 RGSPL 这两个主要指标上,相较于之前的最好方法有了显著提升。
评估方法:
- 使用 REVERIE 数据集进行评估,该数据集包含多个建筑物内的全景图像和目标对象。
- 评估指标包括导航成功率(SR)、Oracle 成功率(OSR)、按路径长度加权的成功率(SPL)以及远程定位成功率(RGS)和按路径长度加权的远程定位成功率(RGSPL)。
Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions
北大董豪组的工作,好一个大语言模型的集成学习。不同的大语言模型各司其职,负责具身工作中的不同模块。“将具有不同能力的大模型作为领域专家,让代理在每一步移动之前与这些专家积极讨论,收集关键信息。”它解决的的 Visual-Language Navigation (VLN),这个领域先前类似的工作有 NavGPT。输出是 trajectory。
他这个工作的思路很好理解,就不多赘述了。至于R2R,
R2R is a dataset for visually-grounded natural language navigation in real buildings.
https://paperswithcode.com/dataset/room-to-room
Skill Transformer: A Monolithic Policy for Mobile Manipulation
“用于解决长期机器人任务,特别是移动操作任务。Skill Transformer 结合了条件序列建模和技能模块化,通过一个端到端训练的变换器(Transformer)架构来预测高级技能(如导航、抓取、放置)和全身低级动作(如基座和手臂运动),从而实现复杂任务的执行。”
这个比较接近 robotics 的具体问题了。
方法概述:
- 输入:Skill Transformer 接收机器人的自我中心和本体感受观察作为输入,包括机器人的深度视觉观察和机器人关节位置、是否持有物体的状态以及基座的自我运动。
- 技能推断:首先,技能推断模块使用因果变换器网络预测当前应执行的skill。
- 动作推断:接着,动作推断模块根据预测的技能、当前观察和前一时间步的动作来预测机器人的低级动作。
- 训练:Skill Transformer 通过自回归方式使用解决完整任务的轨迹进行训练。
实验和评估:
- 实验设置:在 Habitat 2.0 模拟环境中进行实验,使用模拟的 Fetch 机器人执行物体重新排列任务。
- 基线比较:与多种基线方法(包括单体 RL、决策变换器、模块化方法等)进行比较,Skill Transformer 在多个指标上表现更优。
- 鲁棒性测试:通过在测试期间对环境进行干扰(如关闭已打开的抽屉),评估 Skill Transformer 的重新规划能力。
- 消融研究:通过改变政策架构、上下文长度和训练数据集大小,研究这些因素对 Skill Transformer 性能的影响。
值得一提终于见到用Habitat的工作了。
Habitat:https://aihabitat.org/
navigation 和比较细的需要机器人的动作也可以用 habitat。看这个:https://aihabitat.org/ https://ai.meta.com/blog/habitat-20-training-home-assistant-robots-with-faster-simulation-and-new-benchmarks/
See to Touch: Learning Tactile Dexterity through Visual Incentives
这项研究用上触觉了,太细了先不看。
Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
主要是考虑了执行动作前后环境的变化,剩下的没啥了
- 上下文感知规划(Context-Aware Planning, CAP):通过将任务相关的语义上下文(例如,与任务交互的适当对象)纳入行动序列中,提高了代理规划一系列动作的能力。
- 环境感知记忆(Environment-Aware Memory, EAM):通过存储对象状态和它们在交互后的视觉变化(例如,对象被移动到的位置),帮助代理在推断后续行动时考虑到这些变化
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
上一篇论文的 benchmark 用的是 ALFRED (2020)。是 grounding 的评价体系
“We introduce ALFRED, a new benchmark for connecting human language to actions, behaviors, and objects in interactive visual environments.”
输入:需要被操作的物体,scene
输出:expert deomstration,high-level 的自然语言,low-level 的自然语言(如何衡量模型执行结果与自然语言instruction的相似程度?)
Expert demonstrations are composed of an agent’s egocentric visual observations of the environment and what action is taken at each timestep as well as ground-truth interaction masks.
Synthesizing Event-Centric Knowledge Graphs of Daily Activities Using Virtual Space
这个是做知识图谱的。
“简述:论文提出了一种新框架VirtualHome2KG,用于在虚拟空间中生成日常生活活动的合成知识图谱。该框架基于提出的事件为中心的模式和虚拟空间模拟结果,扩展了日常生活活动的合成视频数据和与视频内容相对应的上下文语义数据。因此,可以分析上下文感知的数据,并开发各种传统上由于相关数据的不足和语义信息不足而难以开发的应用。”
Conditionally Combining Robot Skills using Large Language Models
“论文提出了两个贡献。首先,介绍了一个名为“Language-World”的Meta-World基准扩展,允许大型语言模型在模拟机器人环境中使用自然语言查询和脚本化技能进行操作。其次,引入了一种称为计划条件行为克隆(PCBC)的方法,可以使用端到端演示微调高级计划的行为。使用Language-World,表明PCBC能够在各种少数情况中实现强大的性能,通常只需要单个演示即可实现任务泛化。”