MeteorCollector
Let us be, first and above all, kind, then honest
and then let us never forget each other.
About Me
I'm Yuqian Shao (邵钰乾), currently a master's student of Shanghai Jiaotong University.
I major in computer science, and my research interest includes autonomous driving and large langauge/vision models.
Feel free to contact me. Have a nice day.
Education
Tianjin Foreign Languages School (Junior High)
Tianjin Nankai High School (Senior High)
Kuang Yaming Honors School, Nanjing University (Bachelor)
School of Computer Science, Shanghai Jiaotong University (Master, undergraduate)
Academic Publications & Projects
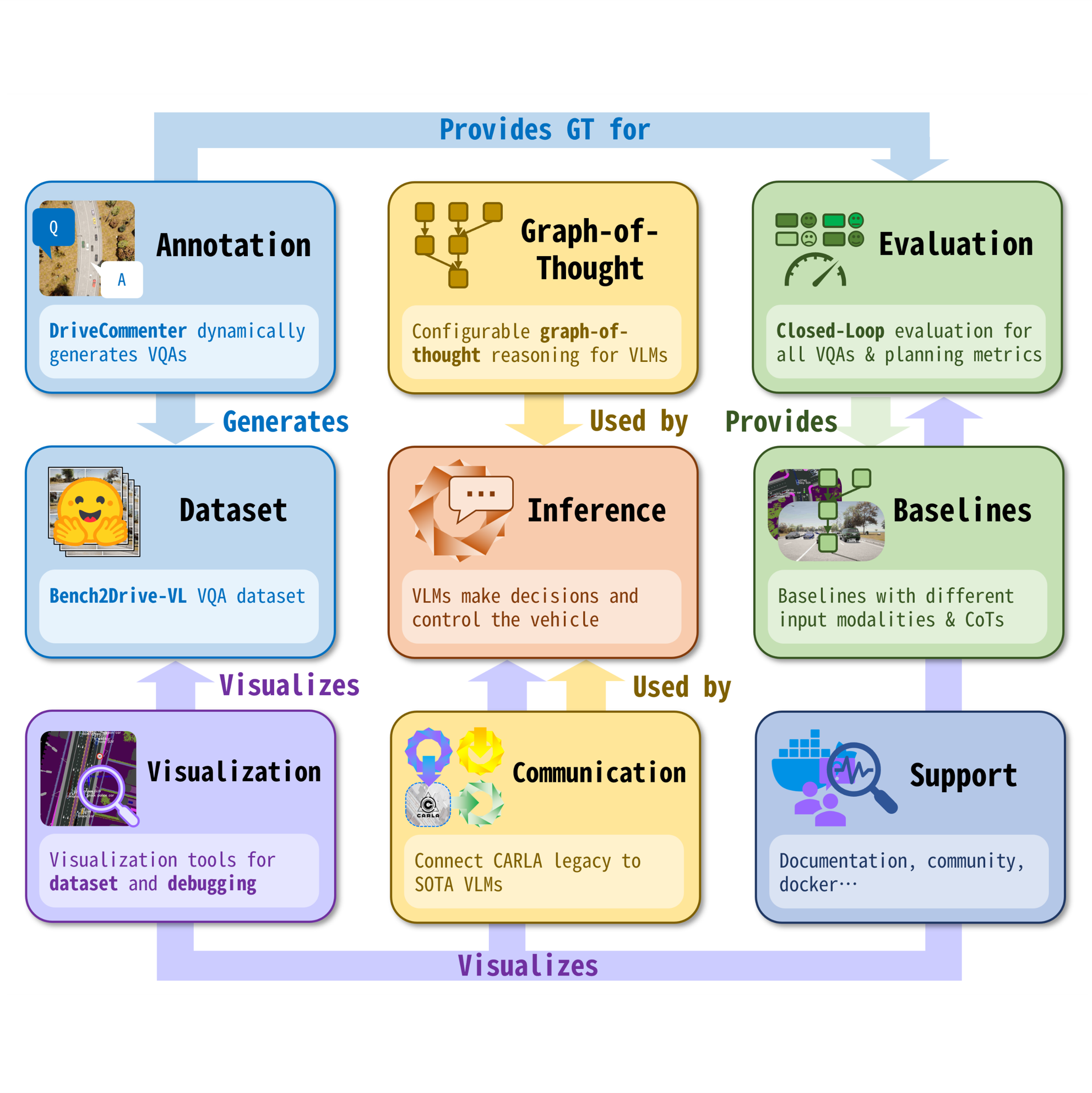
Bench2Drive-VL: Tools and Benchmarks for Closed-Loop Autonomous Driving with Vision-Language Models
Xiaosong Jia*, Yuqian Shao*, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, Junchi Yan, Zuxuan Wu, Yu-Gang Jiang
Under review at JMLR
To achieve a full-task closed-loop evaluation of vision-language models (VLMs) for autonomous driving, we developed an evaluation framework that enables a VLM to control vehicles in the CARLA simulator while dynamically generating driving-related visual question answering (VQA) pairs based on the current scenario, and requiring the VLM to provide answers. To our knowledge, this is the first framework to dynamically generate full-task VQAs. The open-source release includes a complete suite of debugging and visualization tools.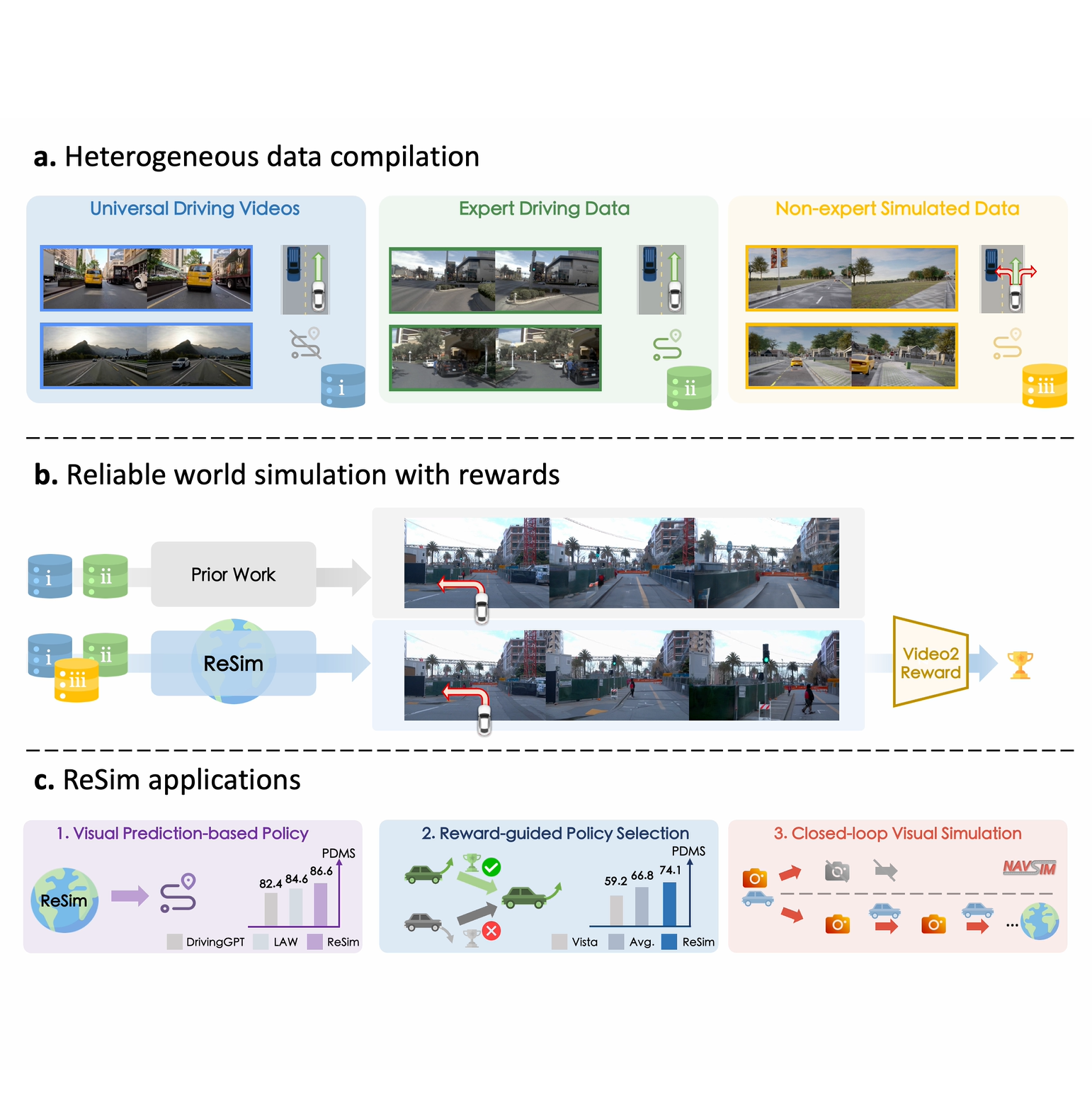
ReSim: Reliable World Simulation for Autonomous Driving
Jiazhi Yang, Kashyap Chitta, Shenyuan Gao, Long Chen, Yuqian Shao, Xiaosong Jia, Hongyang Li, Andreas Geiger, Xiangyu Yue, Li Chen
NeurIPS 2025 spotlight
Developed a controllable diffusion-based world model by combining real-world expert trajectories with diverse non-expert data from CARLA, enabling faithful simulation of both safe and hazardous driving behaviors; achieved up to 44% higher visual fidelity, 50%+ improved controllability, and boosted planning/policy performance on NAVSIM. I'm responsible for the entire CARLA simulator data pipeline.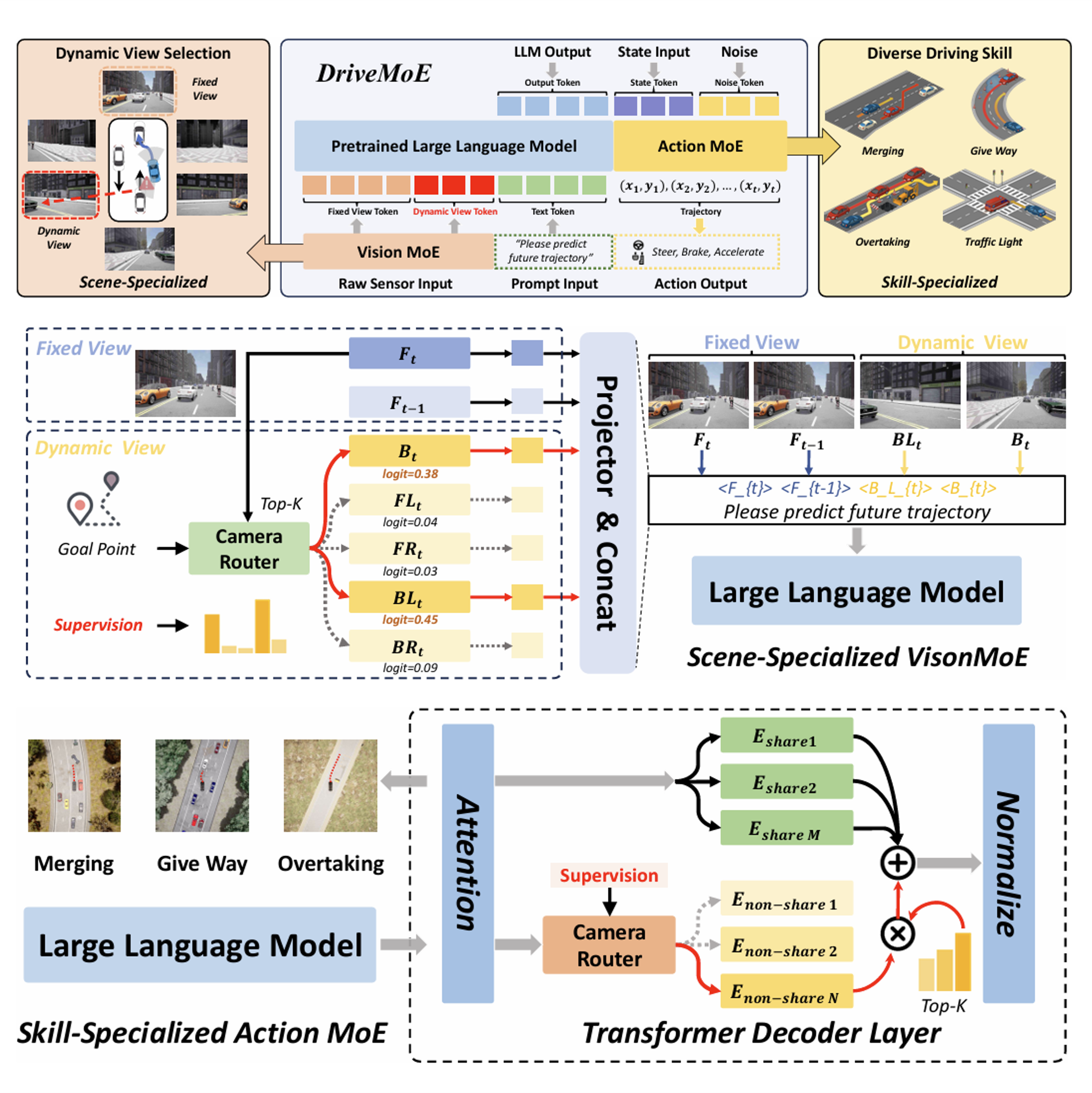
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
Zhenjie Yang*, Yilin Chai*, Xiaosong Jia*, Qifeng Li, Yuqian Shao, Xuekai Zhu, Haisheng Su, Junchi Yan
Under review at ICLR
DriveMoE proposed a MoE framework with scene-specific visual and skill-specific action experts to reduce multi-view redundancy and handle complex driving behaviors, improving efficiency and robustness. I'm responsible for generating ground truth for the scene-specific visual MoE.Other Works

iris
A popular astronomy-related bot, working in 100+ astronomy associations in China.
Visit iris' official site to learn more.
Highlight: Nominated NJU Annual Figure.
Referenced by: StarWhisper, the first Chinese astronomy LLM.

Before university: OrzKMnO4 series
30th July 2017, I formed OrzKMnO4 studio
and made several games in the following 4 years.